一、实验准备
1、导入虚拟机及开启大数据平台
使用提供的
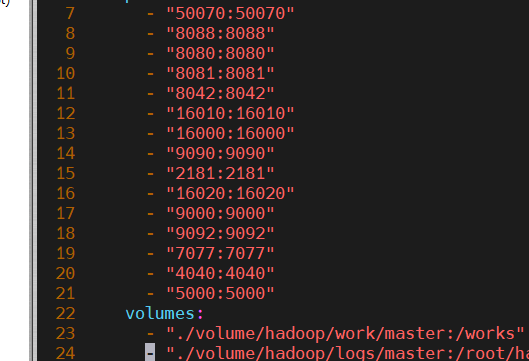
ovf导入虚拟机镜像,用mobaXterm连接虚拟机,打开镜像中的大数据平台文件(hadoop-docker-centos7),在docker-compose.yml中添加端口映射“5000:5000”:
执行
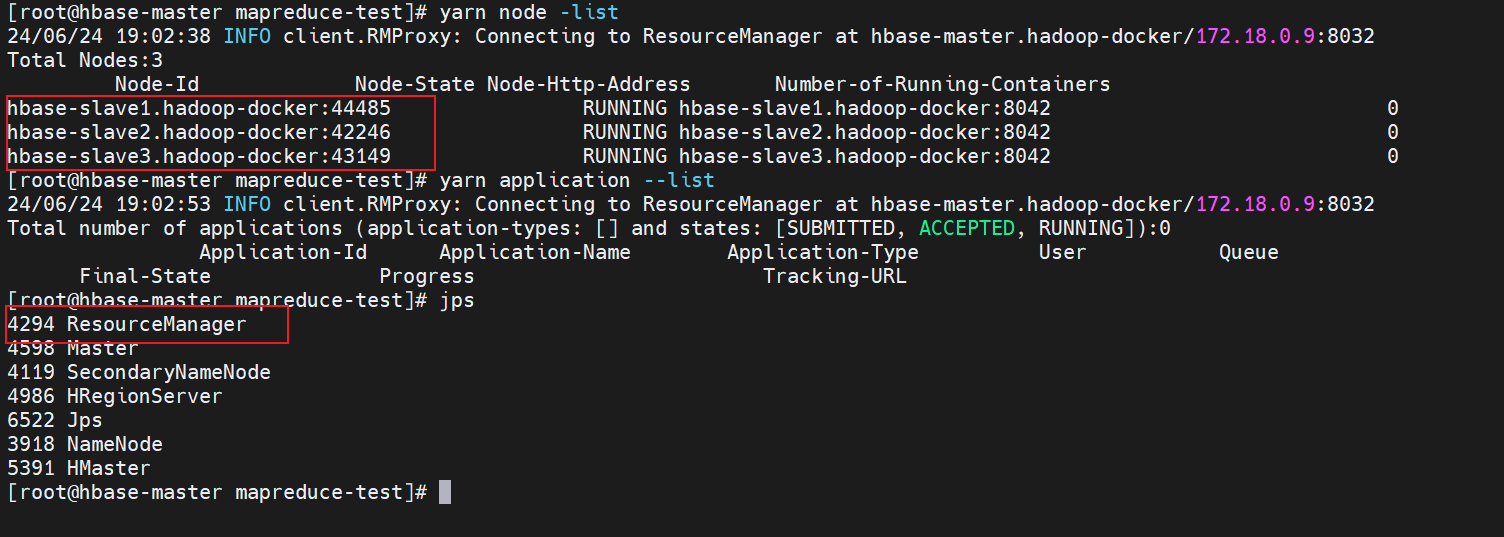
./start-hadoop-images.sh启动大数据平台,主机名称变更为hbase-master。执行yarn node –list查看其他三个节点(hbase-slave1、hbase-slave2、hbase-slave3):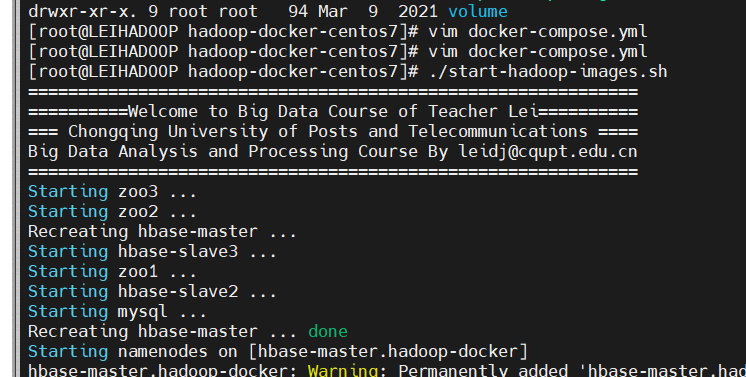
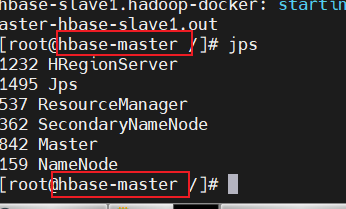
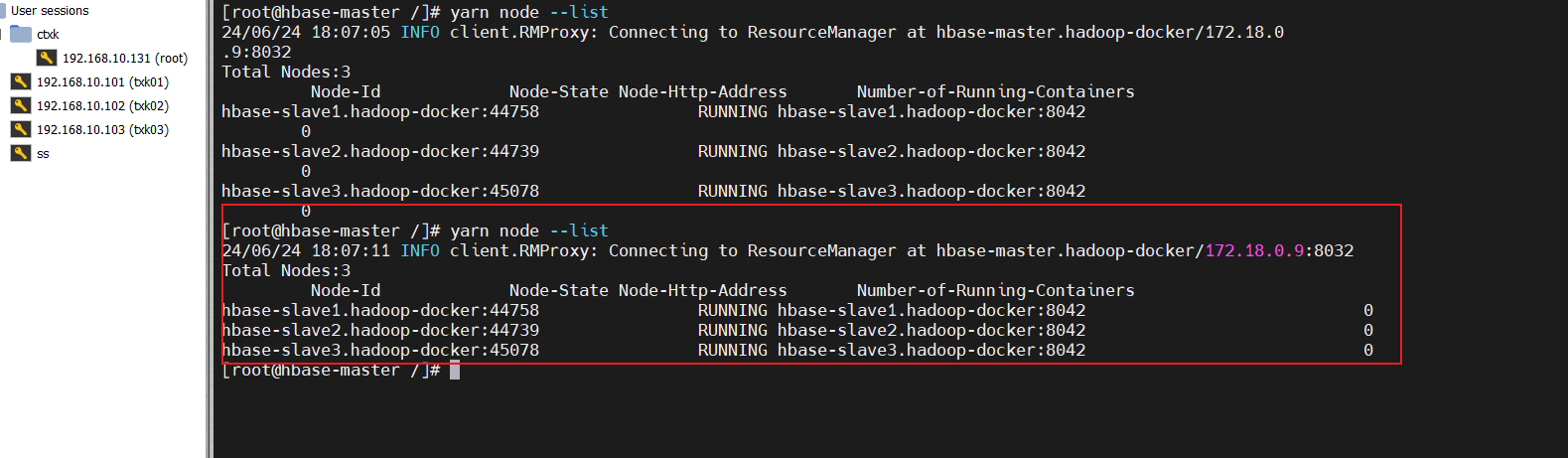
在容器
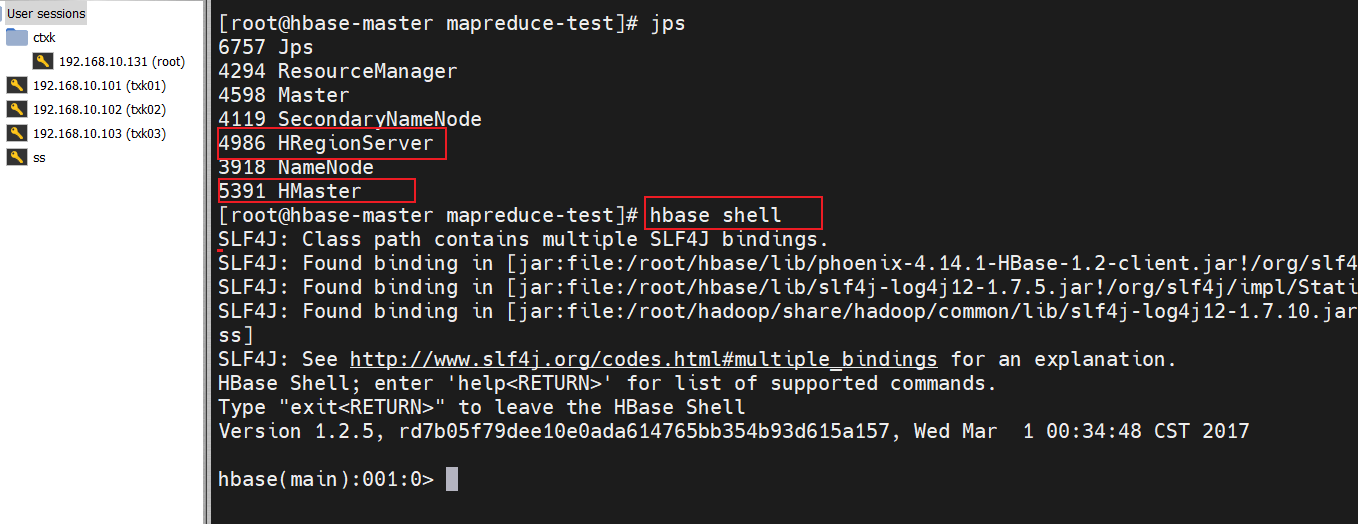
hbase-master中执行jps发现无HMaster进行,然后再执行start-hbase.sh,有则不执行启动hbase的脚本: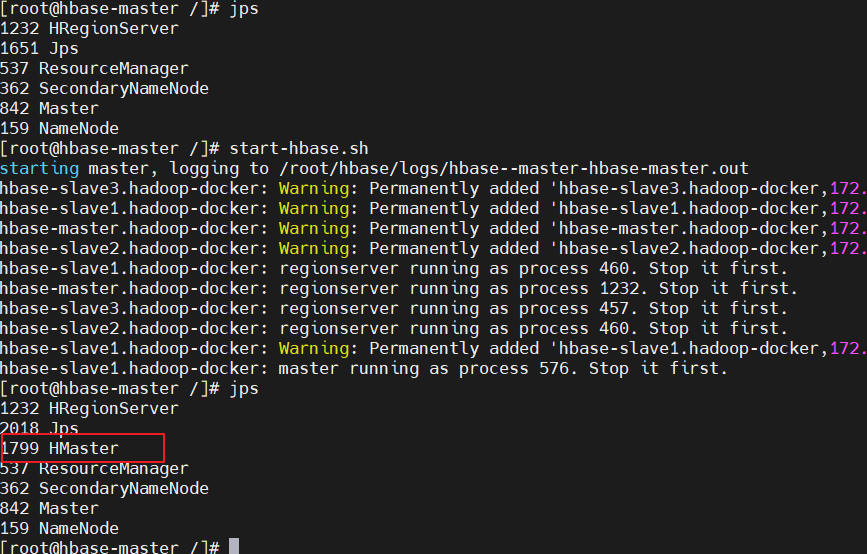
退出大数据平台:退出大数据平台主节点,容器
hbase-master中执行exit。关闭大数据平台:关闭大数据平台,虚拟机操作系统中执行.
/stop-hadoop-images.sh。关闭虚拟机,虚拟机操作系统中执行
shutdown -h now
2、环境检测
大数据平台目前包括的组件有:HDFS、MapRedcue、Yarn、Spark、Scala、HBase、Hive、Zookeeper、Sqoop、 Phoenix、 Python3、 Azkaban、 Kafka、 Sbt、JDK;用于存储元数据数据库为mysql,root账户密码为hadoop。
其中软件版本为:Hadoop: 2.7.2、Spark: 2.1.0、Scala: 2.11.8、HBase: 1.2.5、JDK: openjdk 1.8.0_111、Hive: 2.1.1、Zookeeper: 3.4.10、Sqoop: 1.4.7、Phoenix: 4.14.1-HBase-1.2、Python3: 3.6.0、Azkaban: 3.24.0、Sbt: 1.4.6、Kafka: 2.11-0.10.2.1、MySQL: 5.7。
HDFS
进入大数据平台后再命令行输入jps,出现NameNode和SecondaryNameNode进程。
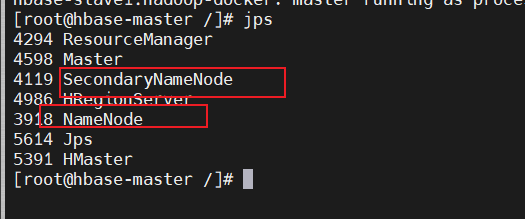
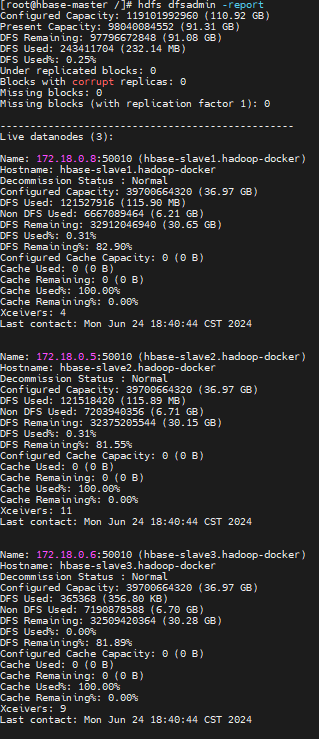
使用命令hdfs dfsadmin -report查看各个节点的当前状态。
MapReduce
使用一个wordcount程序来进行单词计数,判断MapReduce运行是否正常。
进入/code/tests/mapreduce-test/,创建一个words.txt,输入一些单词:
使用hdfs dfs -put words.txt /tmp/上传至hdfs:

使用hadoop jar wordcount.jar /tmp/words.txt /tmp/wordcount执行程序:
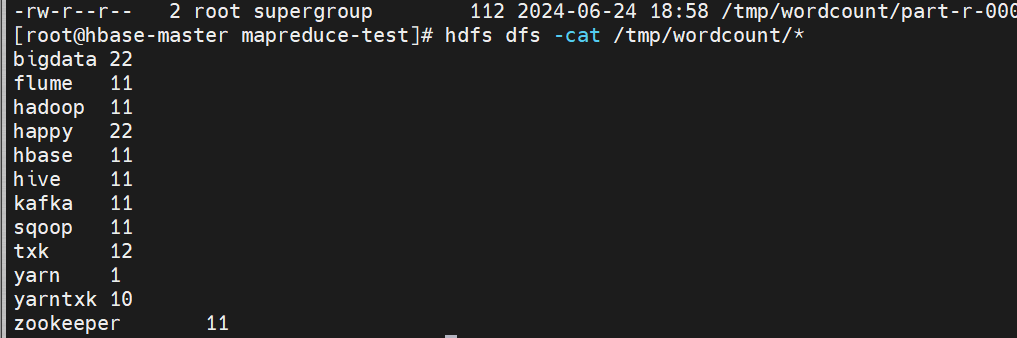
结果被保存在hdfs中,使用hdfs dfs -cat /tmp/wordcount/*查询结果:

yarn
hive
注意:在执行
hive中表和表之间数据导入导出时,需要调用MapReduce者Spark,如果直接退出hive,有可能是设置spark计算引擎问题,请设置计算引擎为MapReduce:set hive.execution.engine=mr。
Hbase
使用hbase shell:
spark
使用spark-shell:
zookeeper
查看docker中的所有容器:
进入zoo1节点,命令docker-compose exec zoo1 bash:

查看Zookeeper服务状态,命令zkServer.sh status:
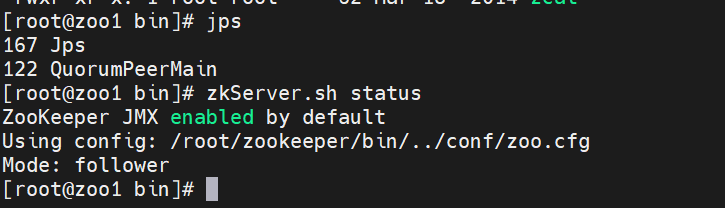
节点是follower角色,正常启动。
启动Zookeeper客户端,命令zkCli.sh:
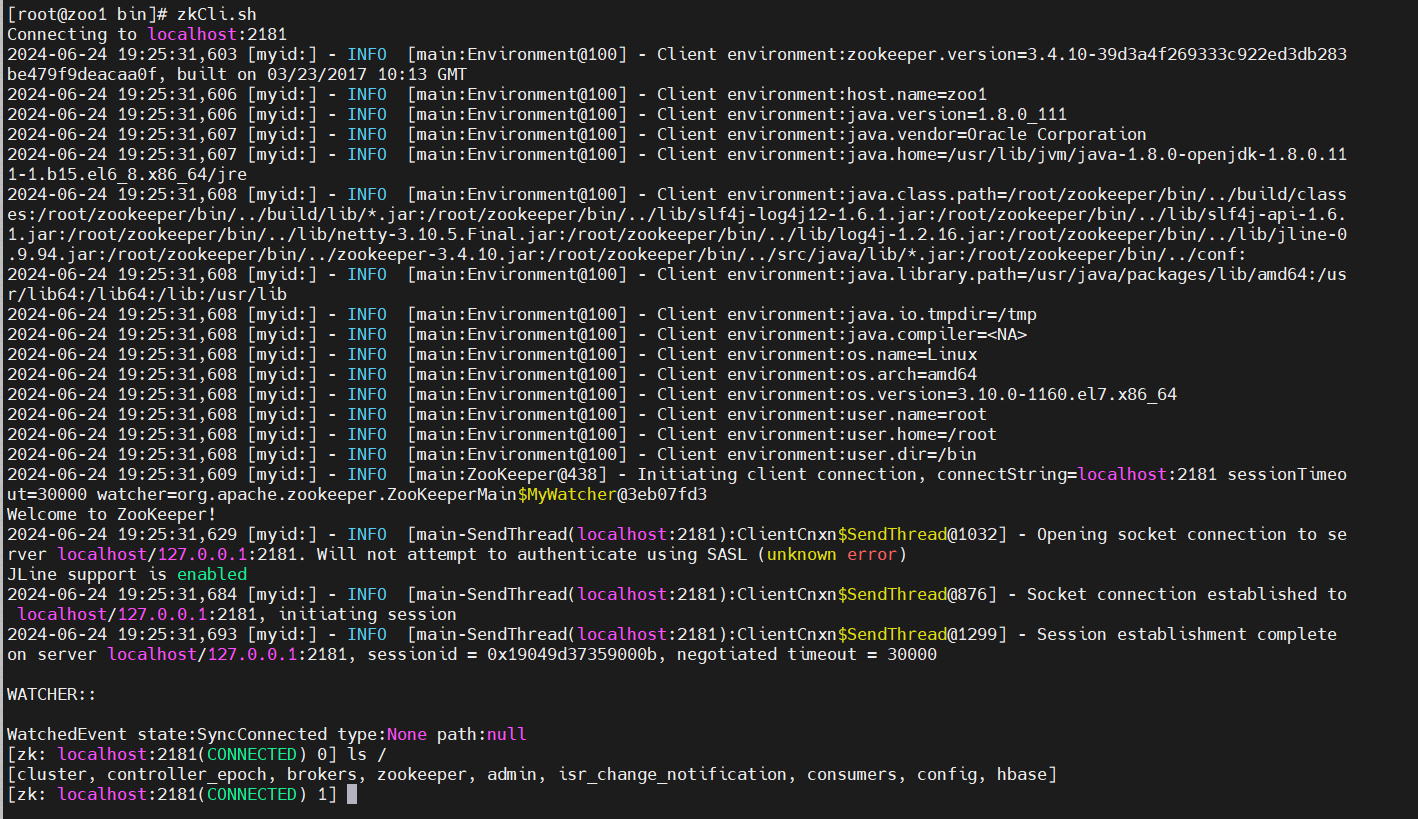
查询hbase在zookeeper服务中注册的RegionServer服务器信息,命令ls2 /hbase/rs:

sbt打包
使用sbt对编译好的scala程序进行打包,直接使用镜像中配置好的sbt进行打包,命令/usr/local/sbt/sbt package:
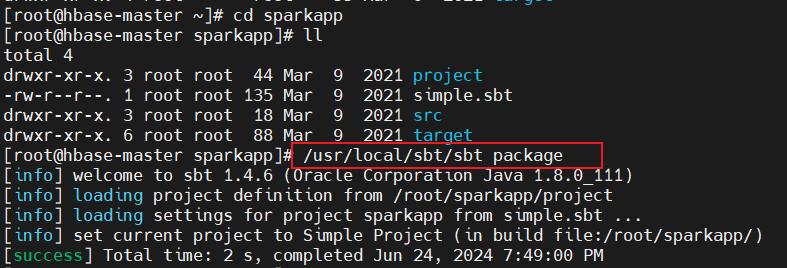
查看生成的目标文件,在target/scala-<version>中:
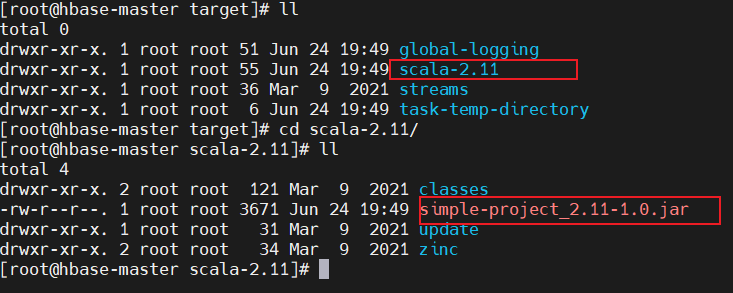
使用spark提交jar包,命令spark-submit --class "SimpleApp" /root/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar:

Azkaban
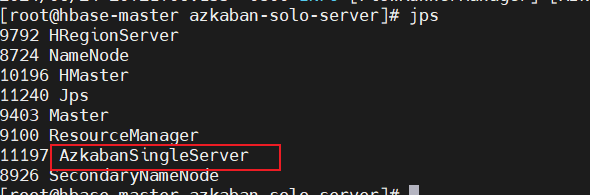
启动
进程中没有AzkabanSingleServer,先启动azkaban.
进入
/root/azkaban-solo-server/,执行bin/azkaban-solo-start.sh:
在windows中访问azkaban图形化界面,
虚拟机ip:8081,用户配置文件在conf/azkaban-users.xml:
kafka
启动kafka,创建一个主题test,查看主题信息,利用kafka提供的命令行工具kafka-console-producer.sh,给kafka集群发送消息,利用kafka-console-consumer.sh接收消息。
kafka启动命令位置

启动kafka服务,命令
bin/kafka-server-start.sh config/server.properties: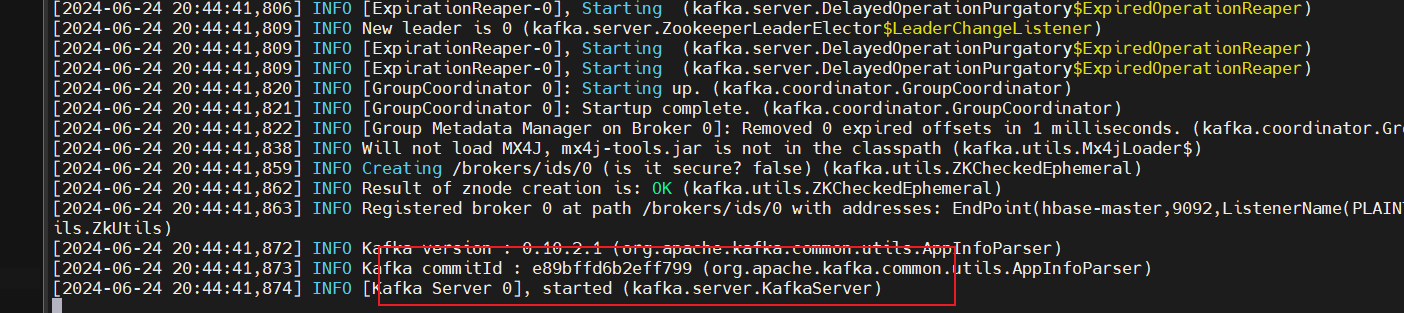
hbase-master的kafka进程:
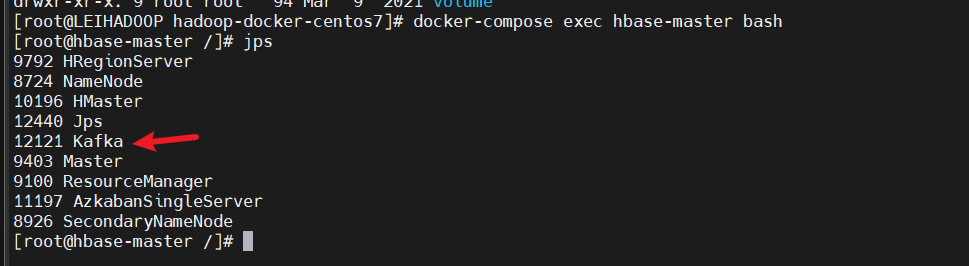
四个节点的kafka的
config/server.properties和/tmp/kafka-logs/meta.properties配置文件id: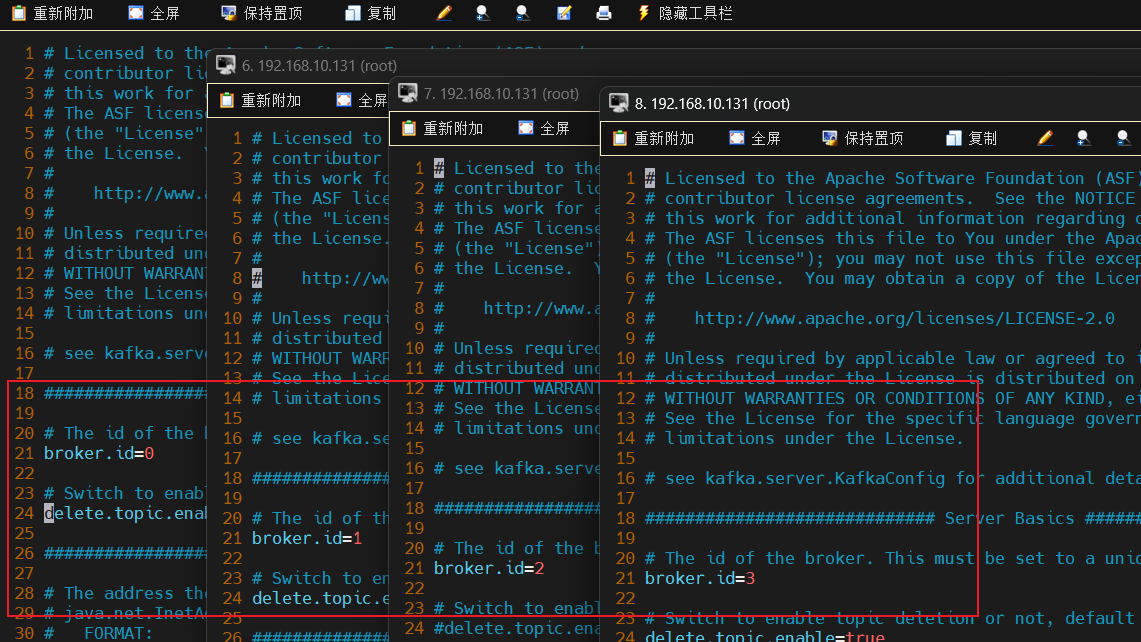
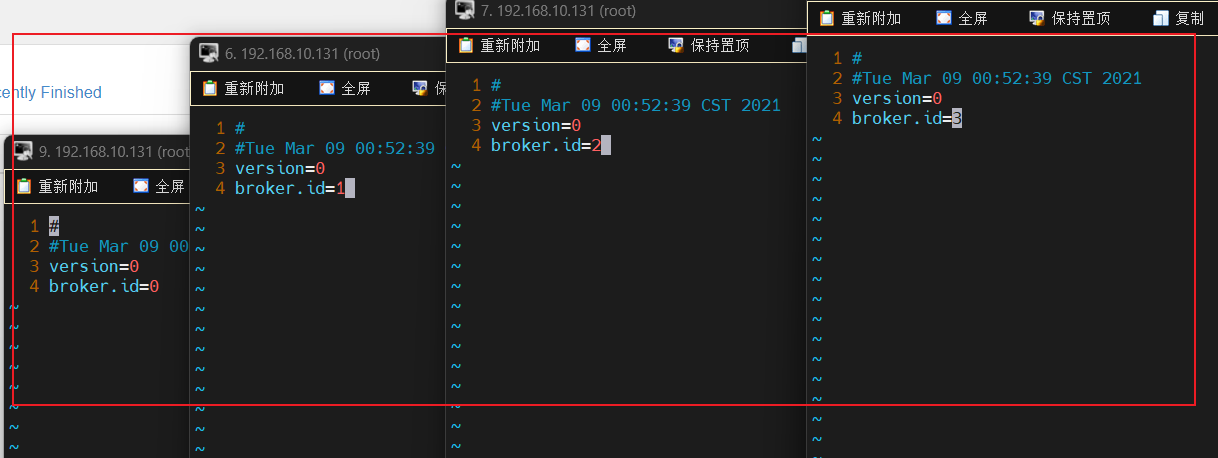
启动各节点的kafka服务:
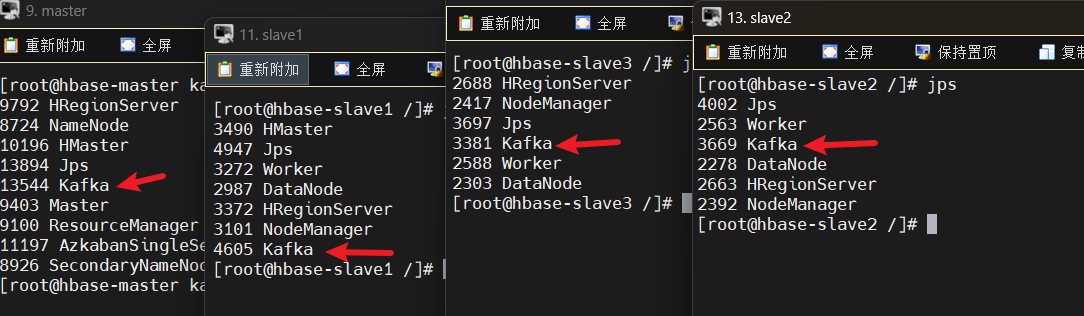
创建test主题,命令
bin/kafka-topics.sh --zookeeper zoo1:2181 --create --replication-factor 4 --partitions 1 --topic testTxk:
当前实验在4个节点上都打开了,因此factor 数量为 4。
测试发送消息,命令
bin/kafka-console-producer.sh --broker-list hbase-master:9092 --topic testTxk:
测试接收消息,命令
bin/kafka-console-consumer.sh --bootsrap-server hbase-master:9092 --topic testTxk --from-beginning:
Phoenix 集成 HBase
先启动Master,命令start-hbase.sh
sqlline.py位置:

到目录下执行sqlline.py:
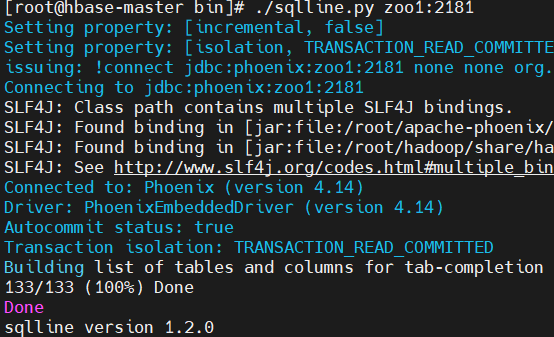
执行
!tables:
3、总结
主要进行了虚拟机的导入安装,对后续需要使用到的工具进行了简单配置,检测和熟悉,为后续实验奠定了基础。
二、大数据批处理系统
0、前言
淘宝双11大数据批处理分析系统,对数据进行分析与预测,涉及数据预处理、存储、查询和可视化分析等数据处理流程及操作,包含Linux、Mysql、Hadoop、Hive、Sqoop、ECharts、Spark等软件的安装和使用方法。
1、数据准备
- 数据通过MobaXterm上传到原虚拟机
上传到hbase-master中,命令
docker cp /tmp/dataset/user_log.csv hbase-master:/home/dbtaobao/dataset;查看前十条数据head -10 user_log.csv: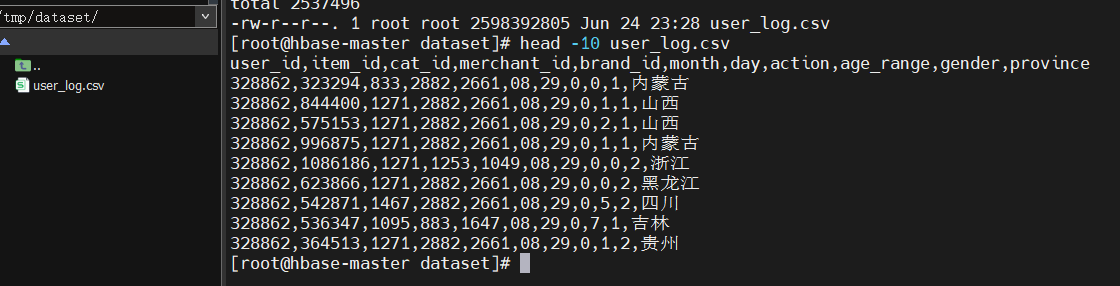
2、数据预处理
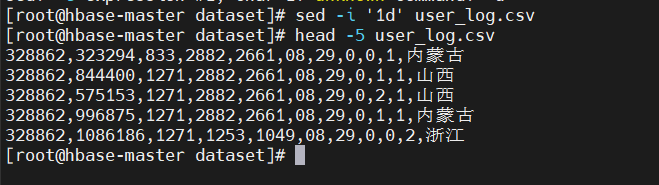
第一行都是字段名称,在导入Hive时不需要,将其删除:
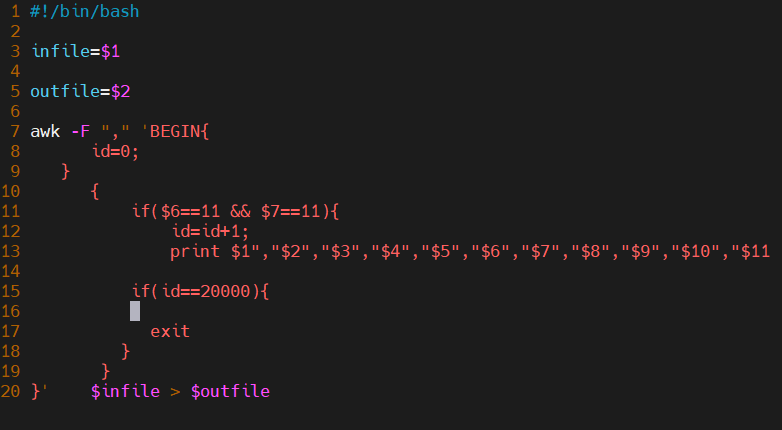
数据集过大,取前20000条数据作为小数据集smalluserlog.csv。建立一个脚本完成截取任务:
导入Hive数据仓库,先在hdfs中创建一个存放数据的dataset文件夹,然后把small_user_log.csv数据上传hdfs。
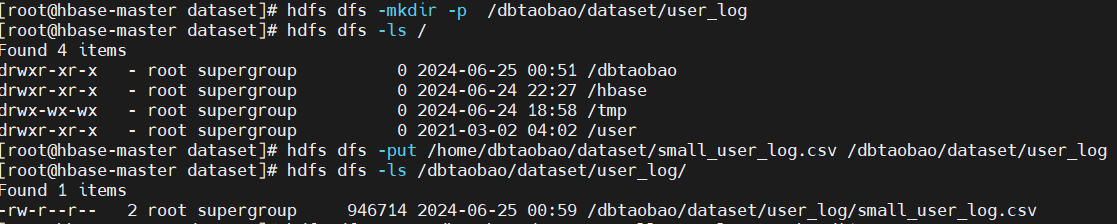
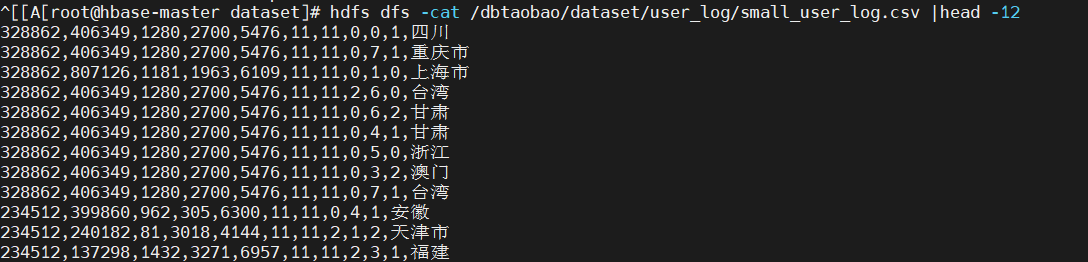
3、启动并配置MySQL
- 进入mysql镜像节点测试:
修改mysql配置文件:
先停止docker容器./stop-hadoop-image,然后启动./start-hadoop-image,进入mysqldocker-compose exec mysql bash,重启mysql服务service mysql restart,自动退出mysql,重启mysql容器docker restart
mysql。
4、Hive的简单使用
内部表:也叫管理表表⽬录会创建在集群上的{hive.metastore.warehouse.dir}下的相应的库对应的⽬录中。默认创建的表就是内部表。
外部表:外部表需要使⽤关键字"external",外部表会根据创建表时LOCATION指定的路径来创建⽬录, 如果没有指定LOCATION,则位置跟内部表相同,⼀般使⽤的是第三⽅提供的或者公⽤的数据。建表语法(必须指定关键字external) create external table tableName(id int,name string) [location 'path'];
建立dbtaobao数据库:
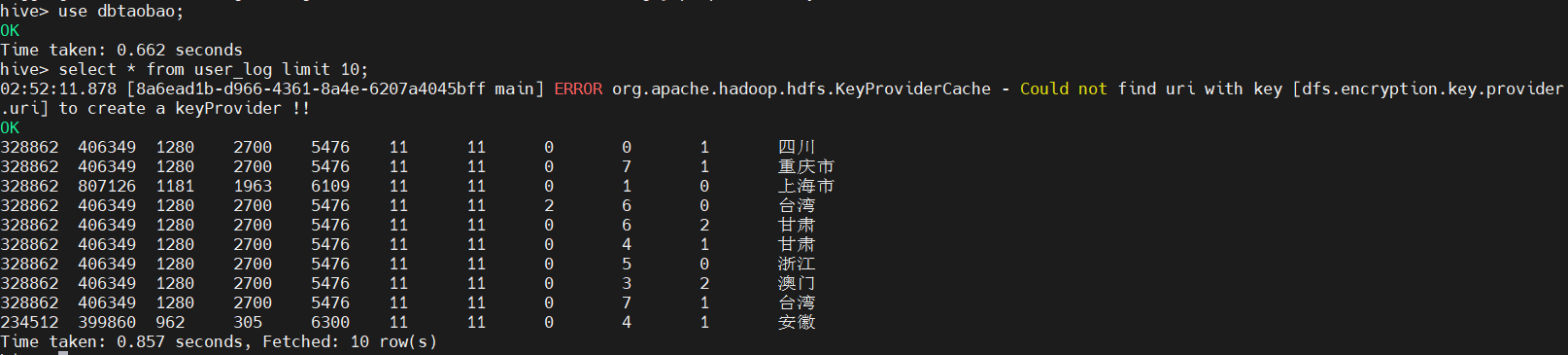
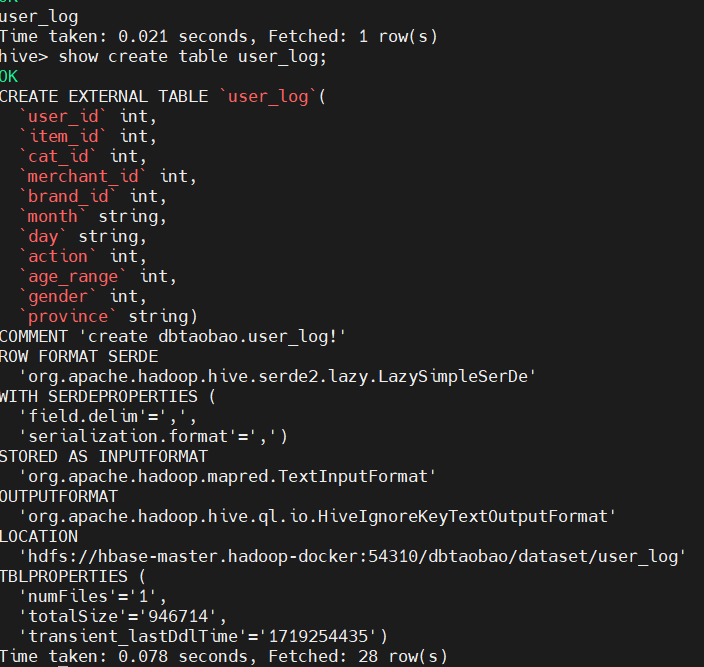
创建外部表user_log,查询结果:
操作hive
执行如下命令:

结果如下:
利用Hive进行数据分析与处理
简单查询分析:
查询条数统计分析:
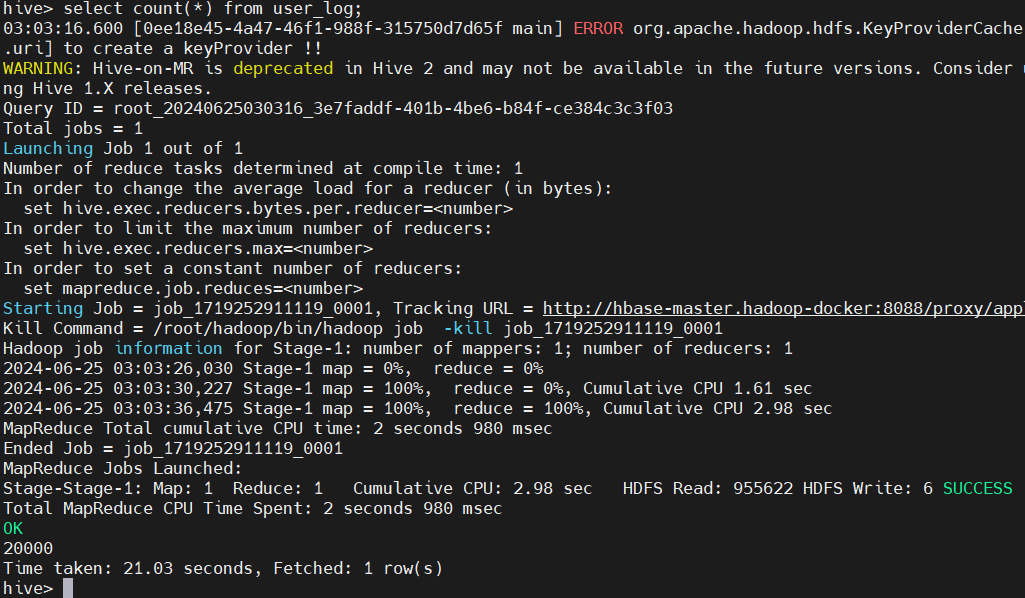
不重复数据查询:
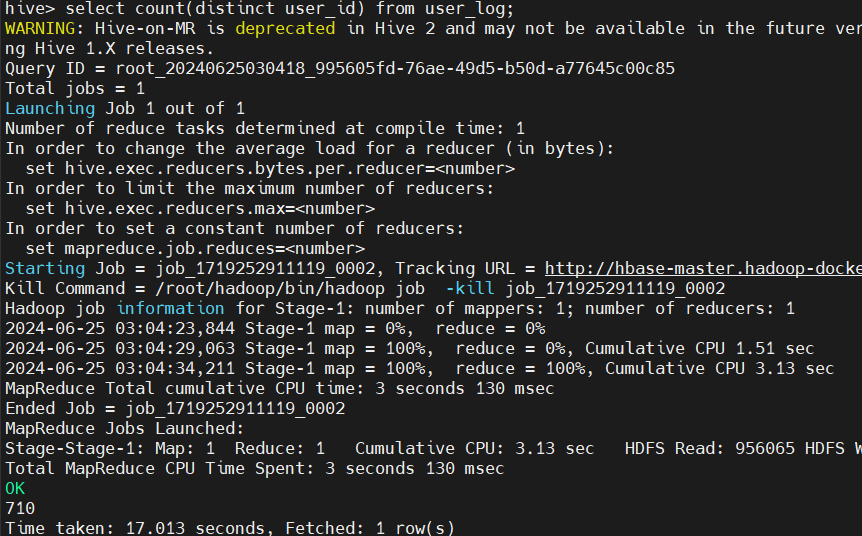
5、Hive的数据处理和分析
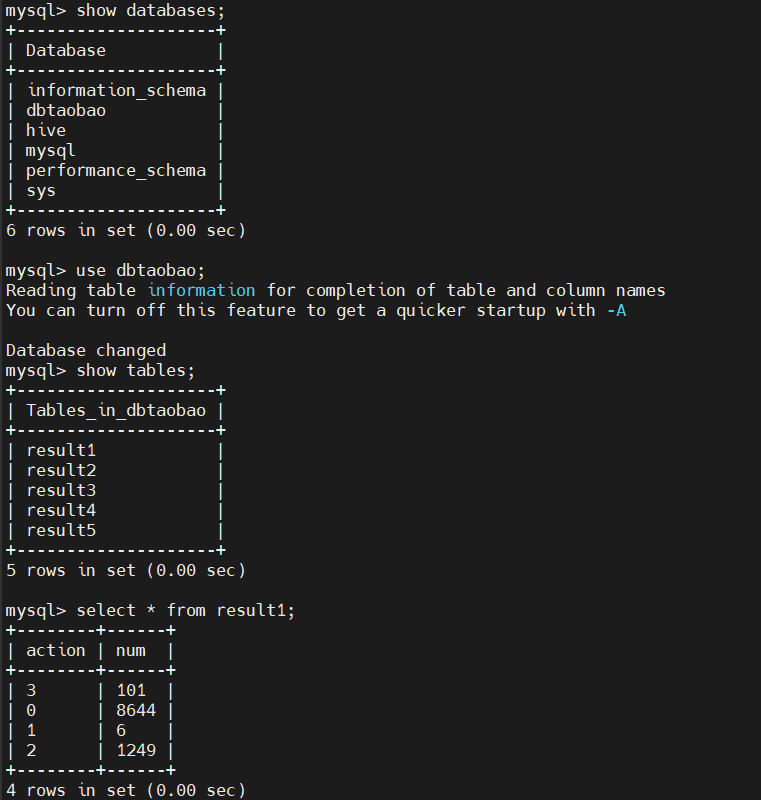
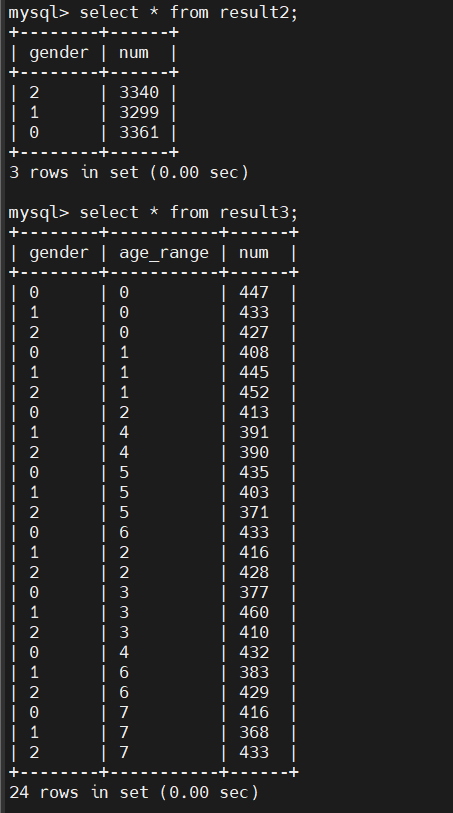
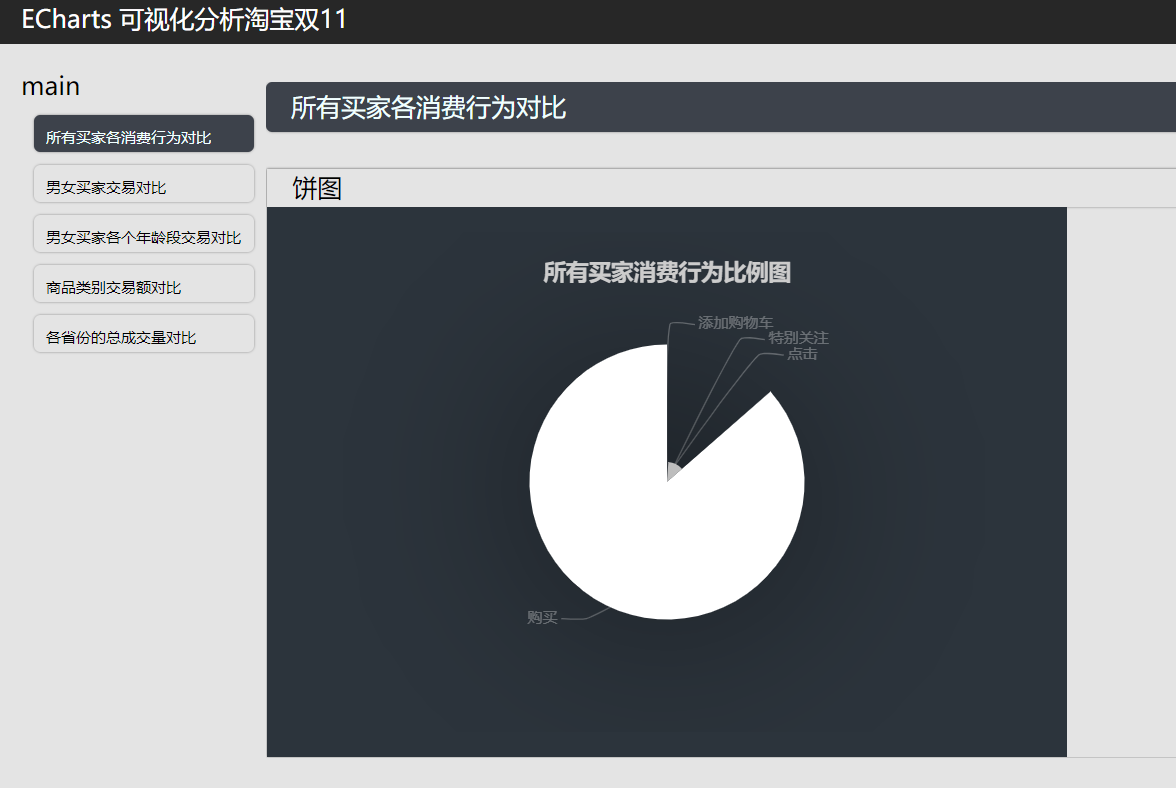
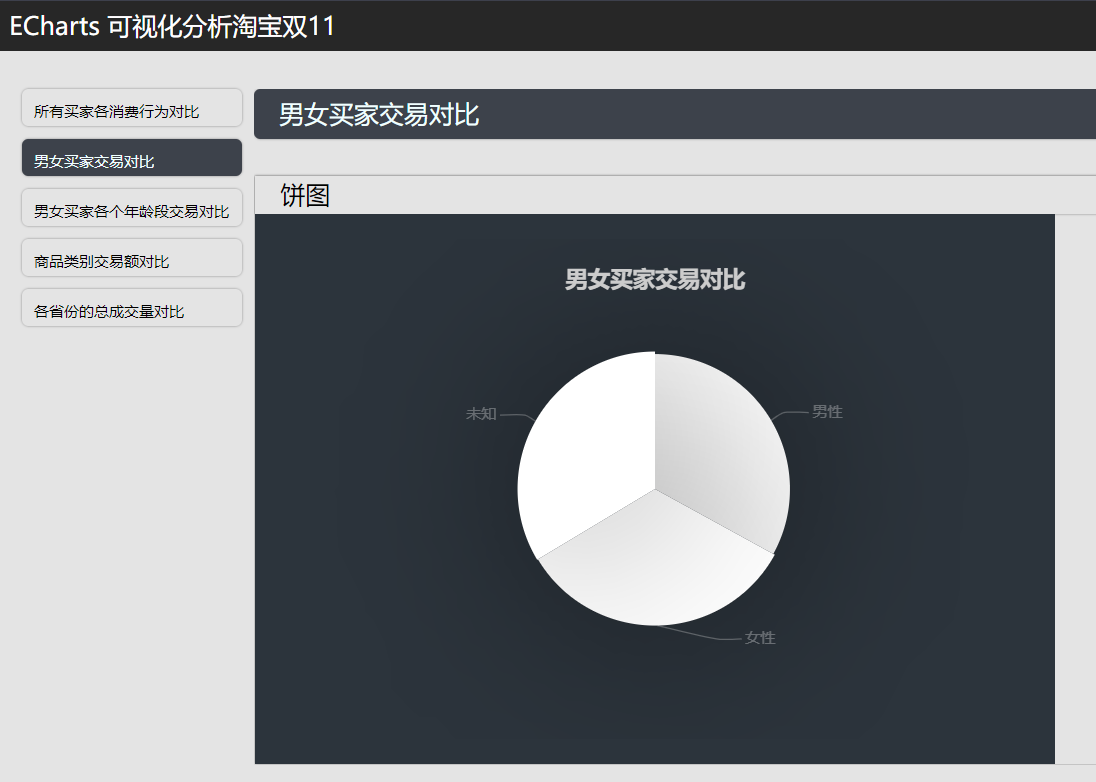
男女买家交易对比
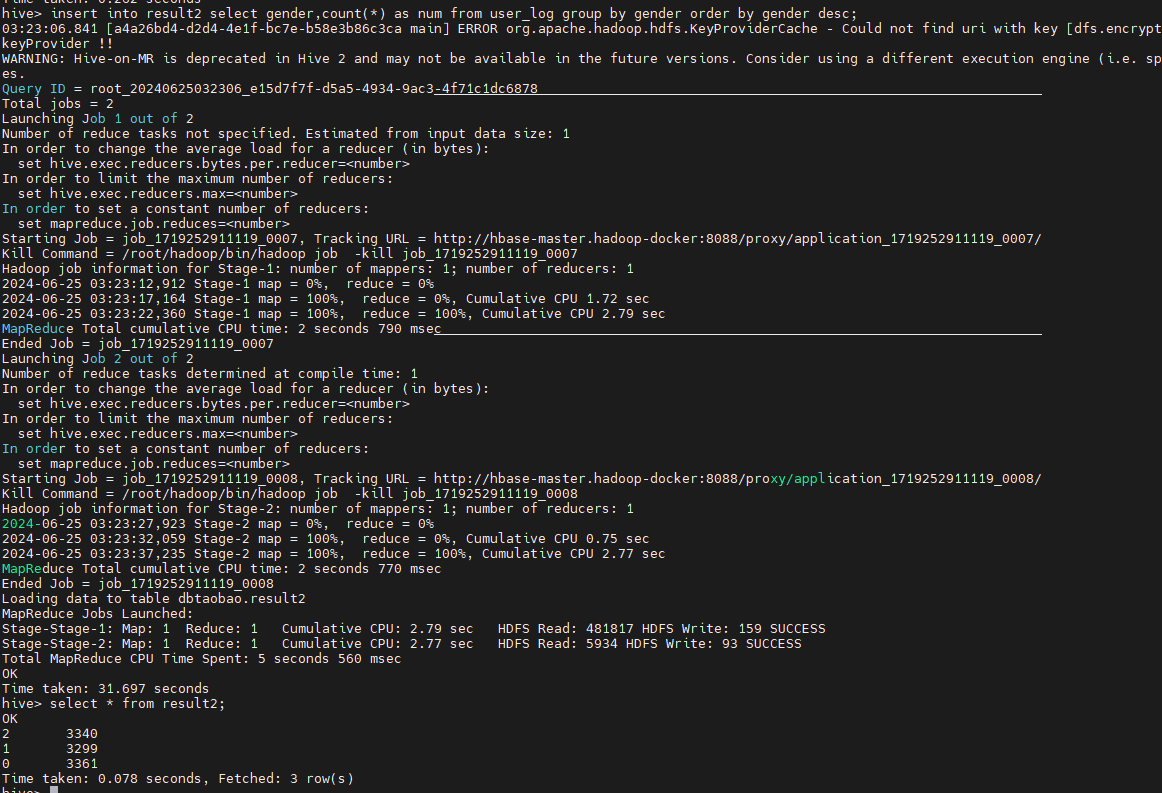
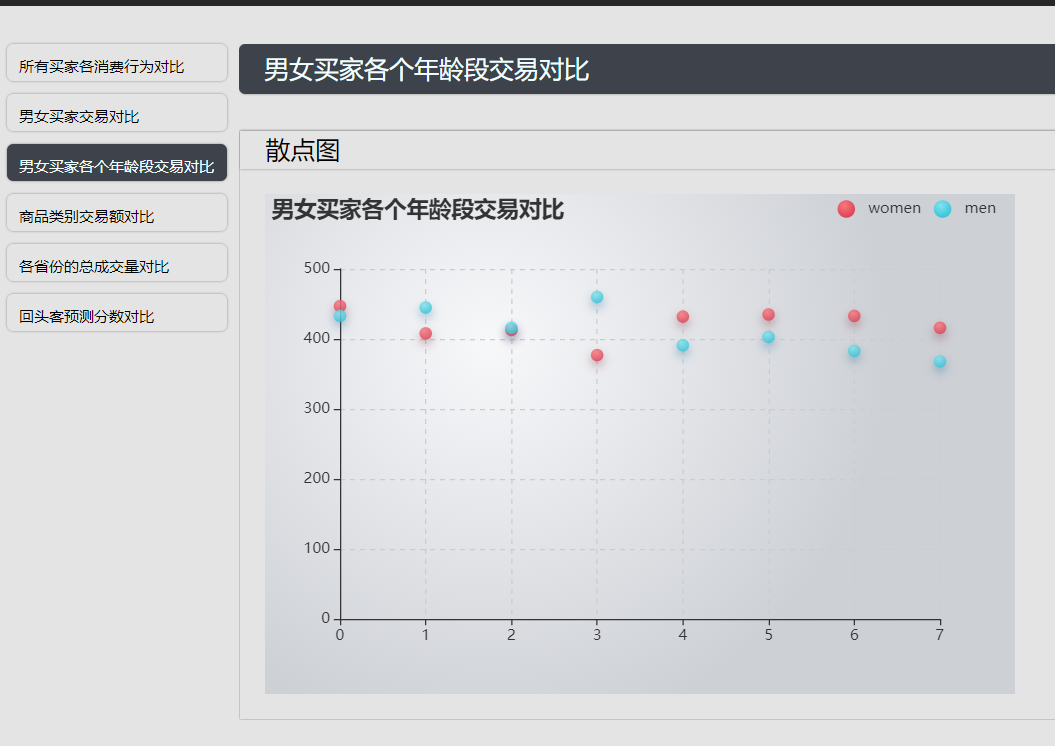
男女买家各个年龄段交易对比:
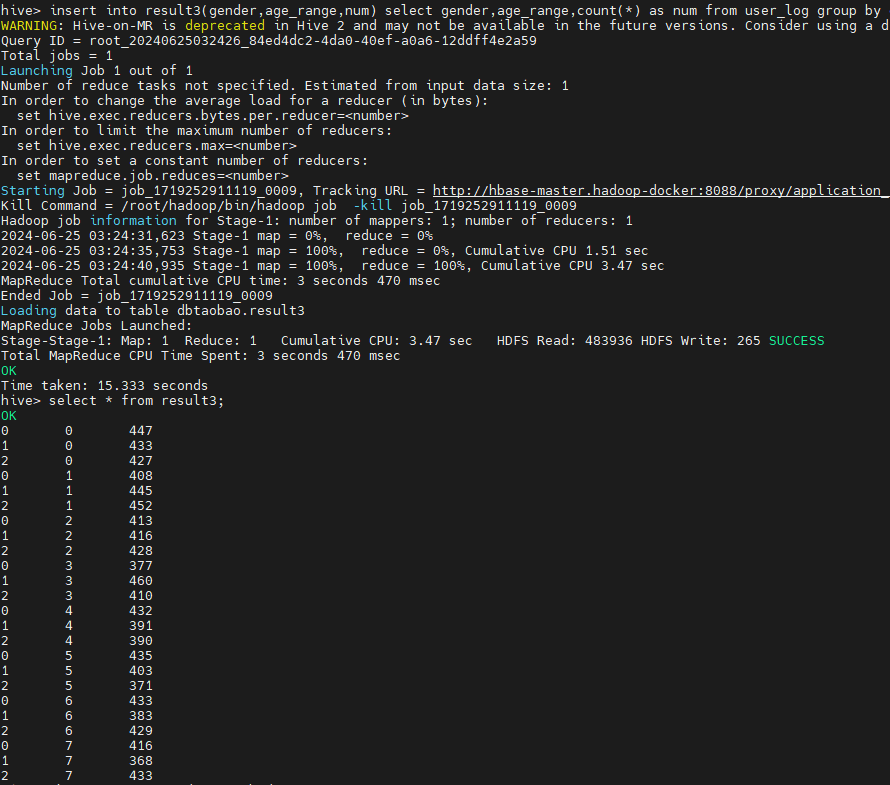
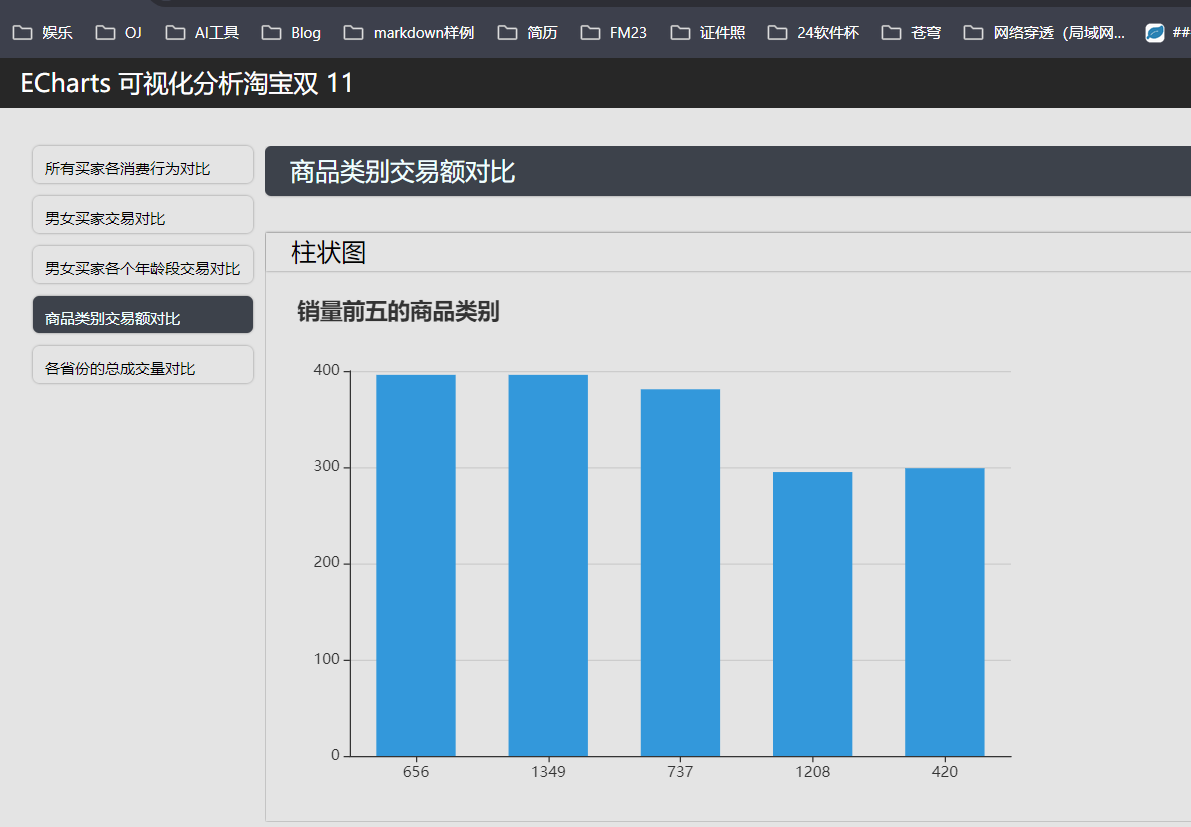
获取销量前五的商品类别:
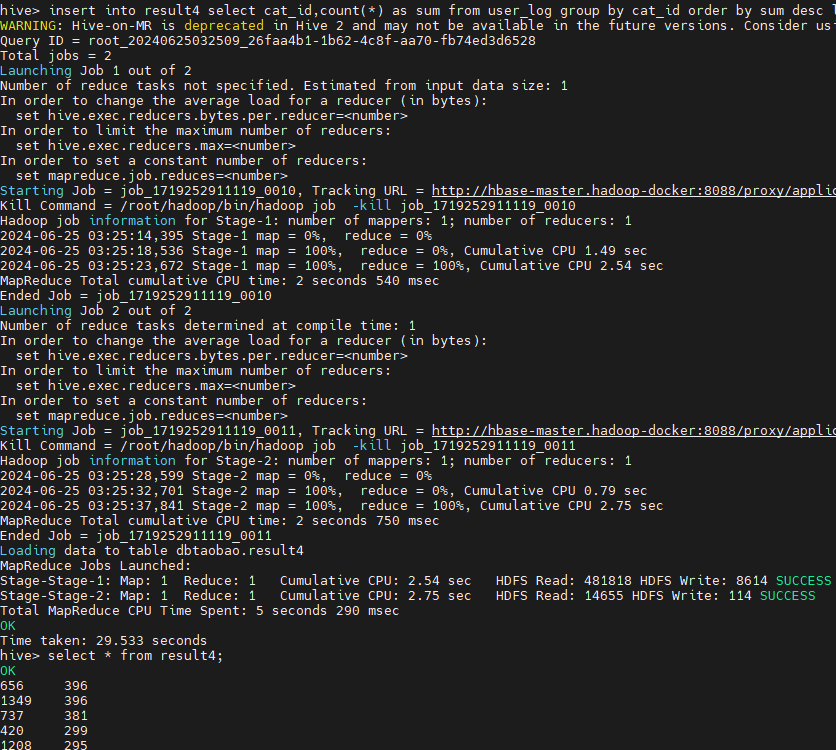
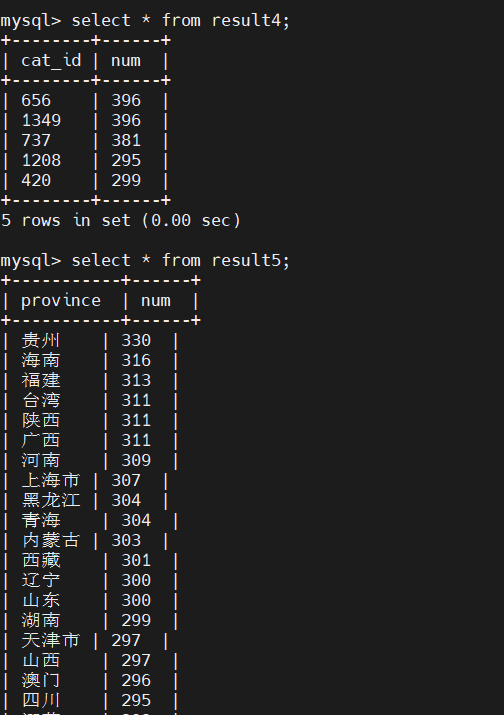
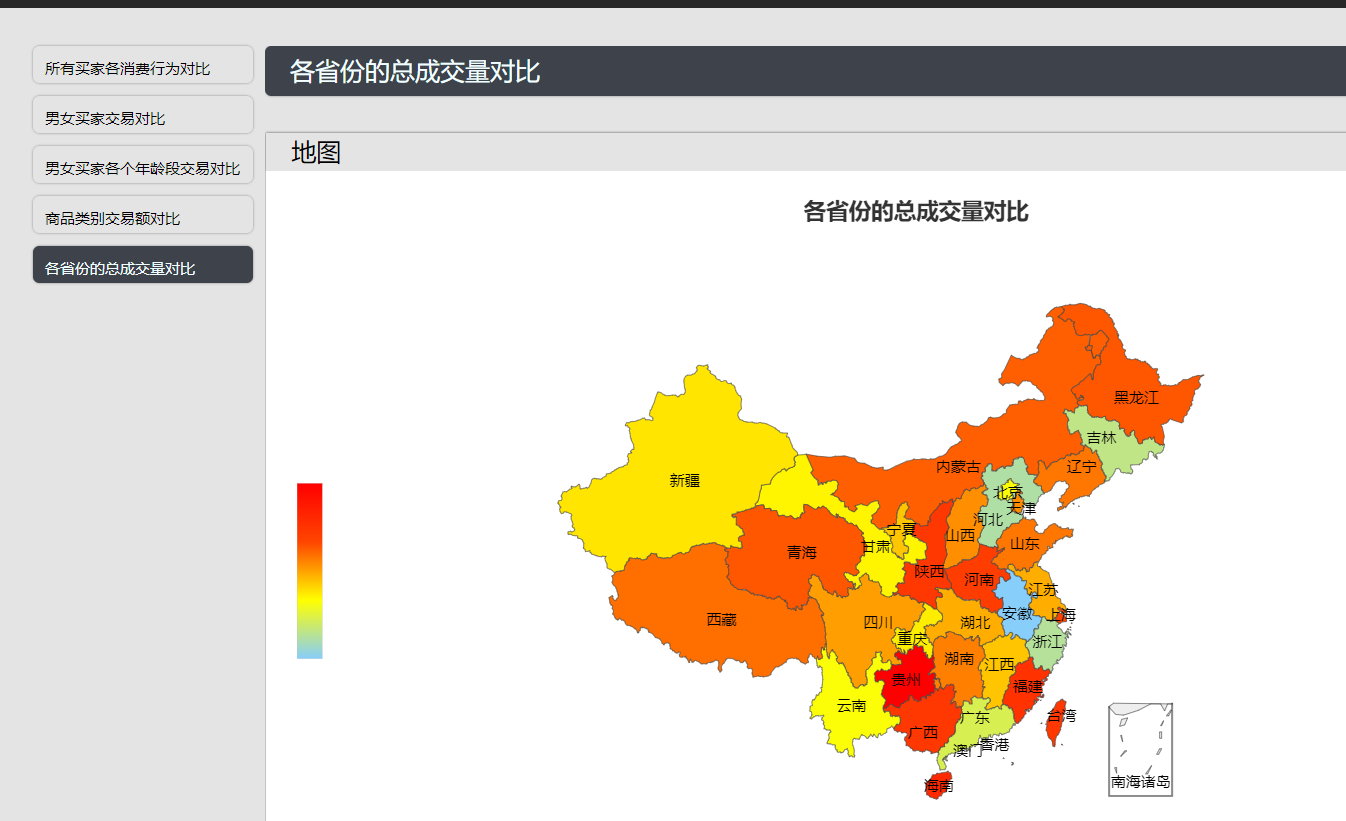
各个省份的的总成交量对比:
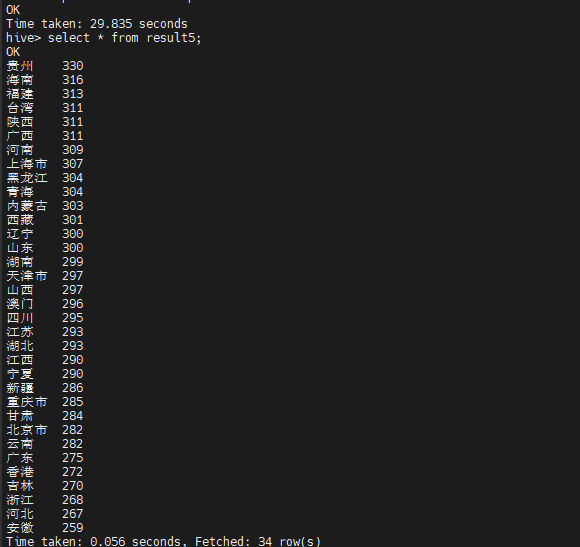
6、从hive导入数据到mysql
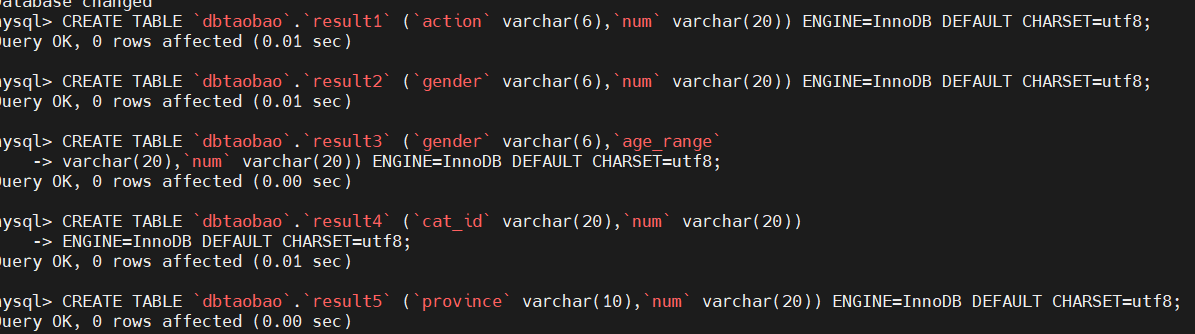
在mysql中创建5个新表,设置编码为utf-8:
1 | CREATE TABLE `dbtaobao`.`result1` (`action` varchar(6),`num` varchar(20)) |
进入master节点中使用sqoop将hive中相关数据导入mysql,5条语句分别对应5个表格:
1 | sqoop export --connect jdbc:mysql://mysql:3306/dbtaobao --username root --password hadoop --table result1 --export-dir '/user/hive/warehouse/dbtaobao.db/result1' --fields-terminated-by ',' |
7、idea+Tomcat+ECharts展示数据
创建webapp项目然后导入mysql依赖
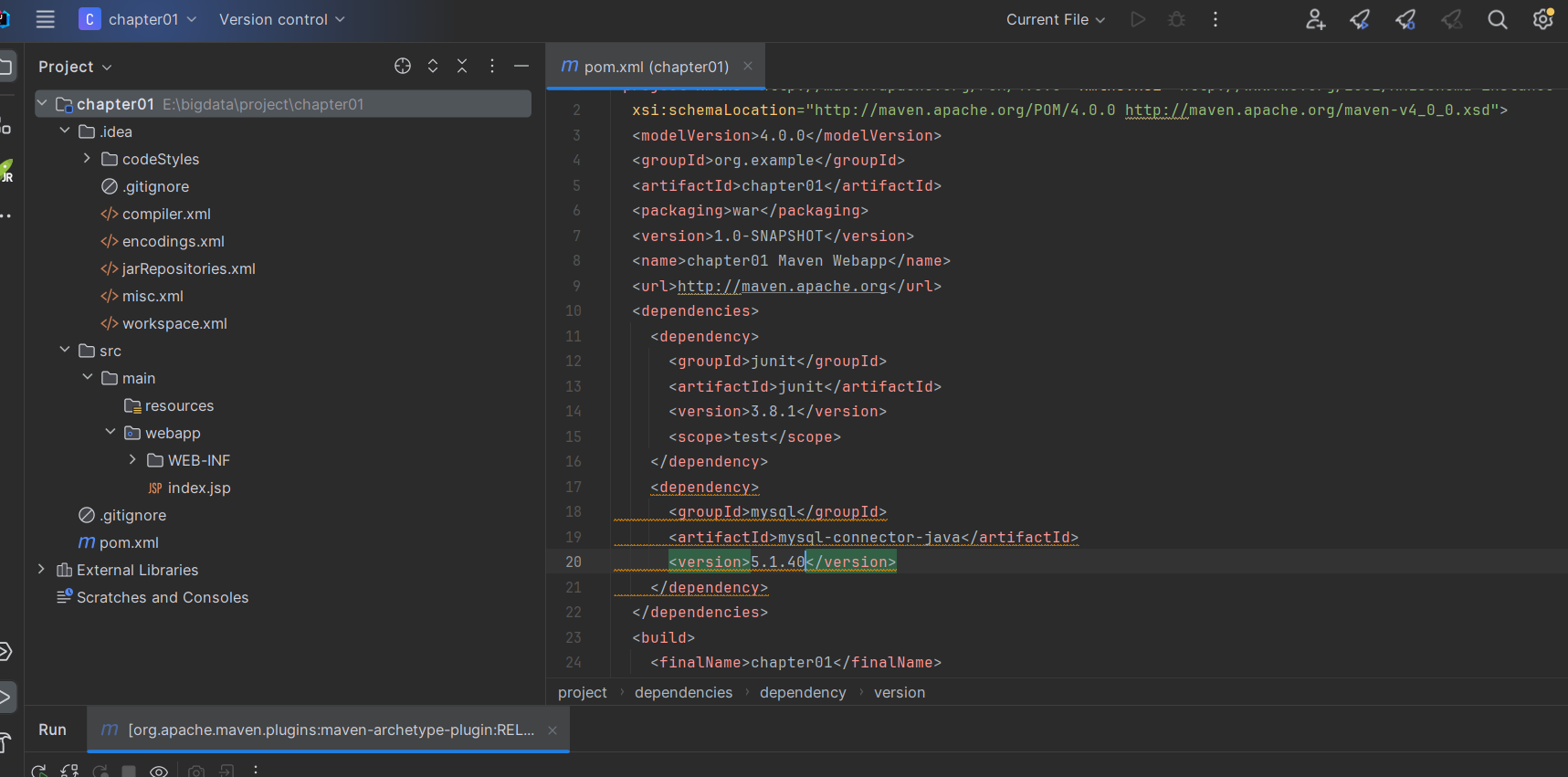
配置tomcat服务
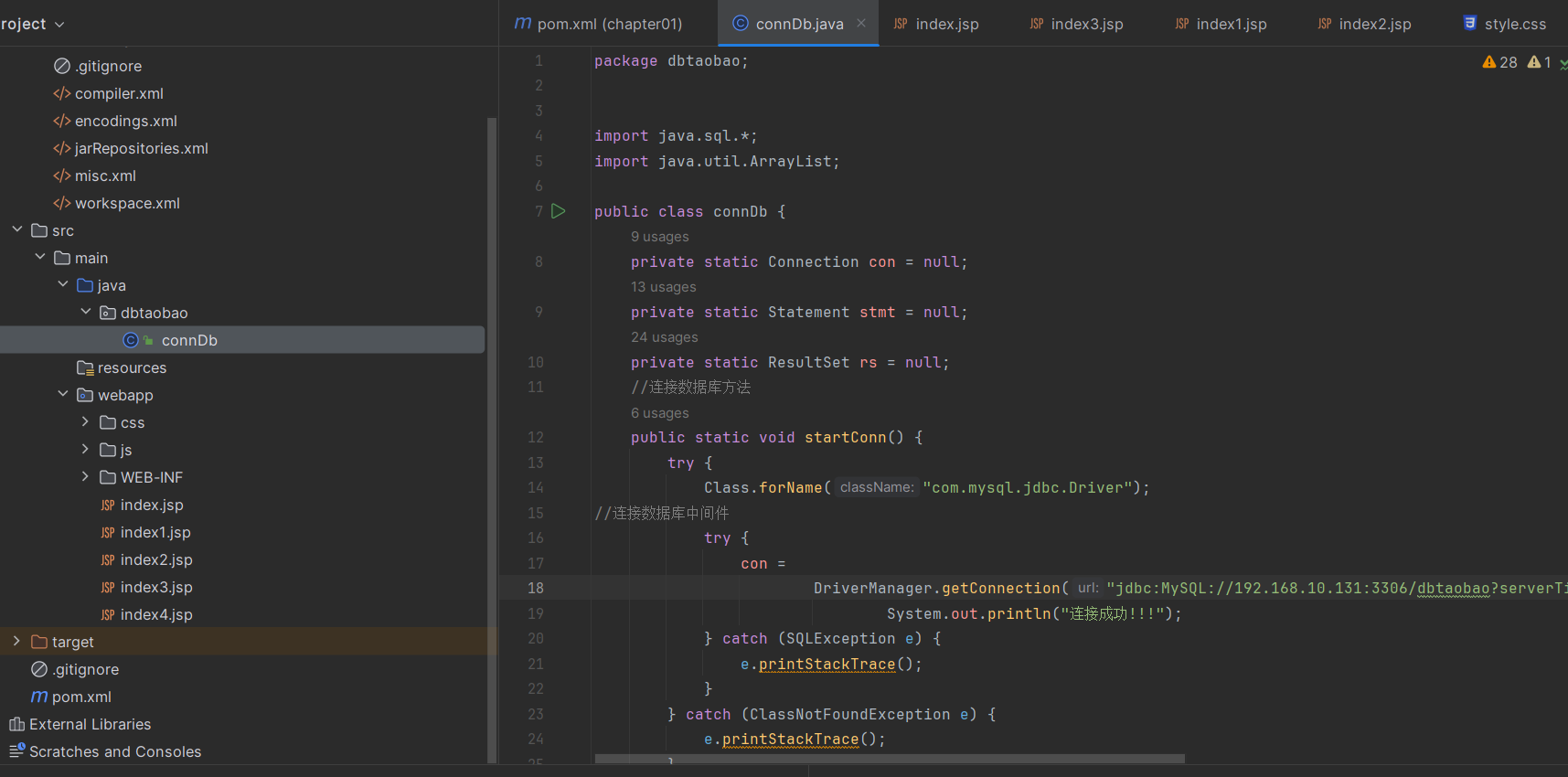
修改mysql的IP地址,添加相应的jsp,js和css代码
运行效果展示
8、总结
主要是在mysql配置utf8时遇到容器崩溃,mysql节点被破环进入不了,最后将docker全部格式化,重新处理数据和配置其他环境。
hive中,在需要调用MapReduce或spark的任务中,需要设置引擎:set hive.execution.engine=mr;
三、大数据查询分析计算系统
0、前言
NBA 统计大数据查询分析计算系统,涉及虚拟机镜像的导入、linux 系统的使用、hbase 的使用、phoenix
的使用,以及 python 调用 hbase 的 api、scala 调用 spark 的 api,搭建 flask 程序。

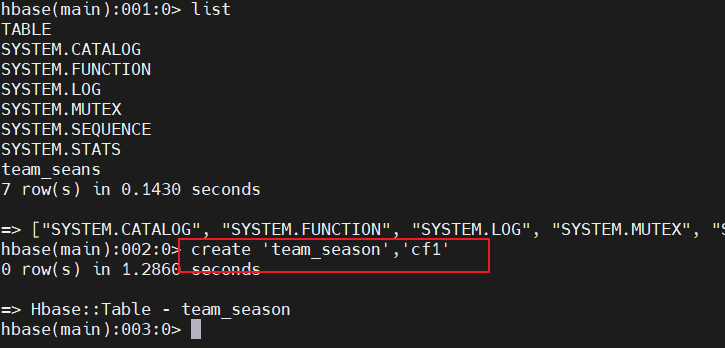
1、HBase创建表
进入 hbabse shell
执行create 'team_season','cf1'创建表,设置表名和列族名:
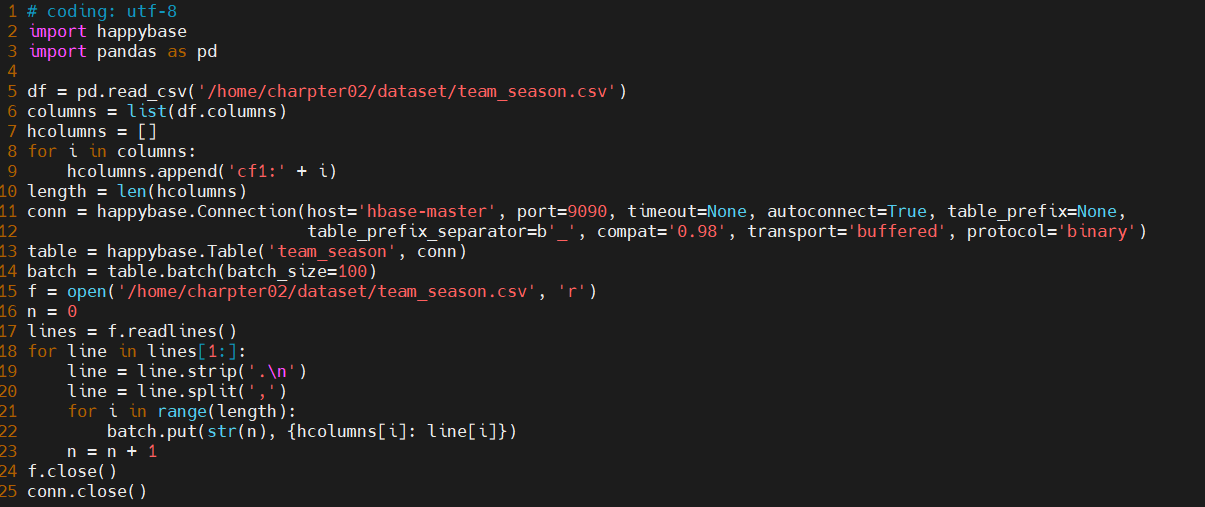
2、编写python脚本批量导入数据至hbase中
- 退出hbase后,新建文件夹/home/NBA/,在里面新建python文件
tohbase.py:

将数据集
team_season.csv数据上传到虚拟机中:传输命令:

数据展示:
执行 hbase-daemon.sh start thrift 让程序能够连接到 hbase,并检查9090端口是否可用:

安装 happybase和pandas:
1
2
3
4
5
6由于要用到 happybase,pandas 包。需要安装
需要安装 happybase
pip3 install happybase
安装 pandas
pip3 install pandas执行之前编写的 python 脚本文件,导入数据,
python3 tohbase.py执行.py 文件:
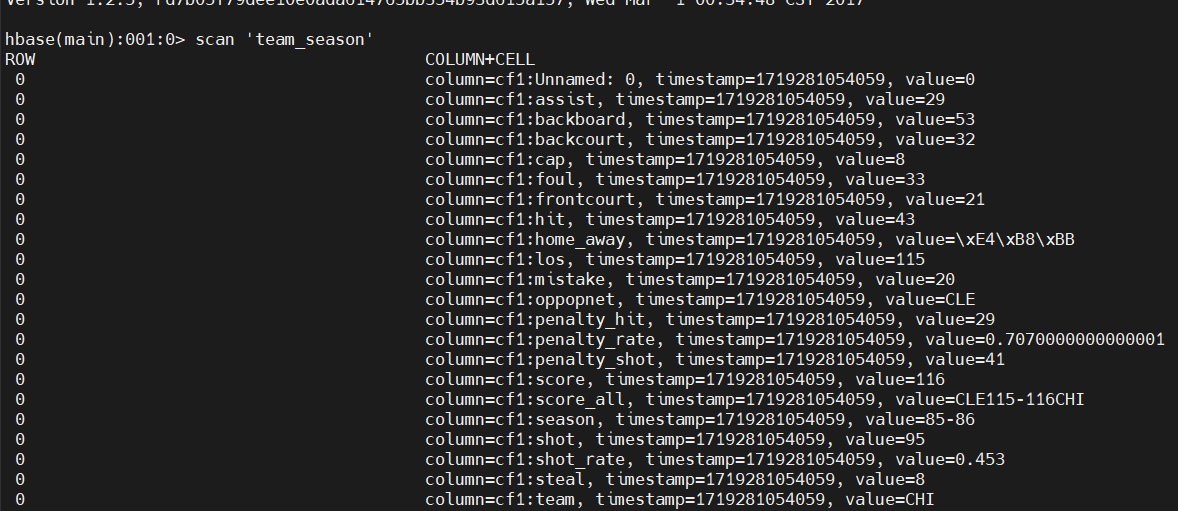
进入 hbase shell,用 scan 扫描表显示:
3、phoenix 建立与 hbase 相映射的表
执行 sqlline.py 启动 phoenix,使用
!tables命令查看表:

在phoenix中创建映射的表,再用
!tables查看表:

然后就可以使用sql语句进行,Phoenix 是一个 SQL 层,用于与 HBase 进行交互,提供了 JDBC 驱动程序和兼容 ANSI SQL 的查询接口。它使得开发者可以用熟悉的 SQL 语言来查询 HBase 中的数据:
4、搭建Flask
安装virtualenv,创建一个独立的python环境myapp:
1
pip3 install virtualenv
进入虚拟环境,安装flask:
1
2
3cd myapp/bin
source activate
pip install flask
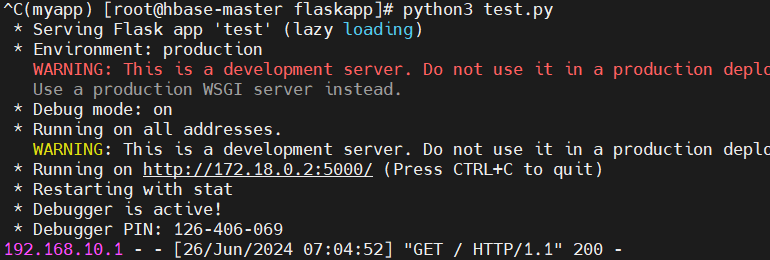
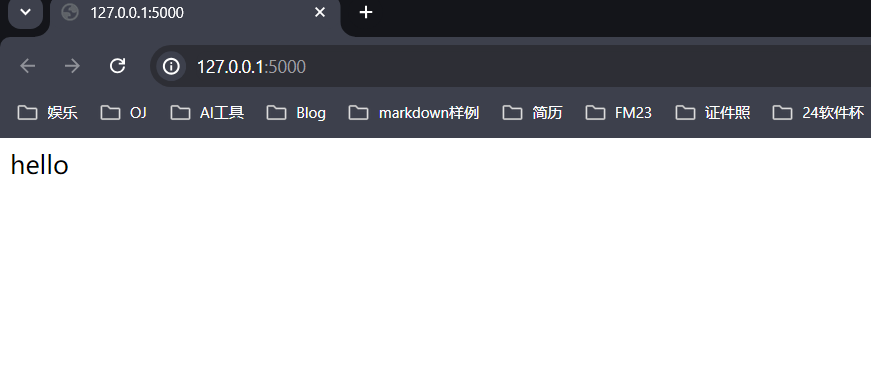
测试flask:
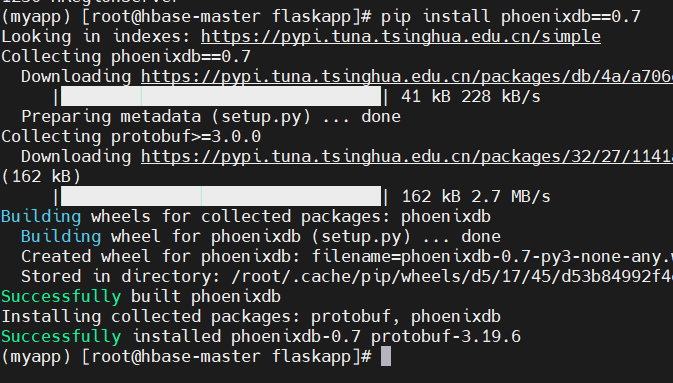
在 myapp 虚拟环境下安装 phoenixdb
1
pip install phoenixdb==0.7
启动queryserver服务
在虚拟环境myapp中测试phoenixdb 连接是否正常
1
2
3
4
5
6
7import phoenixdb
import phoenixdb.cursor
database_url = 'http://localhost:8765/'
conn = phoenixdb.connect(database_url, autocommit=True)
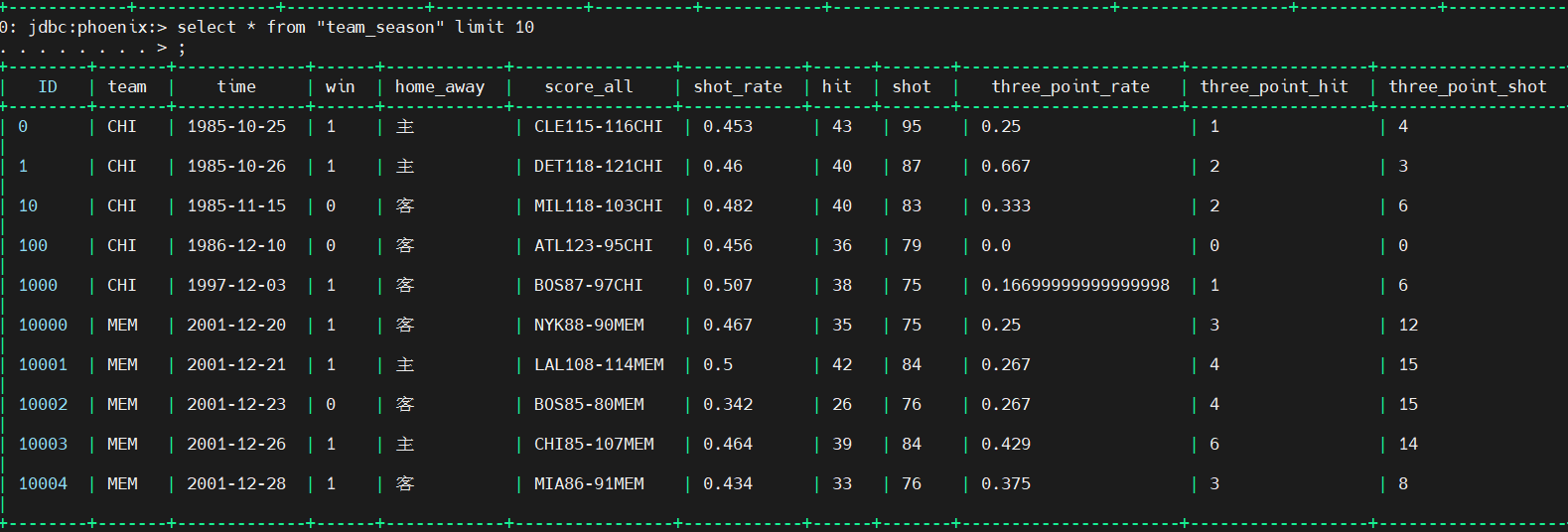
cursor = conn.cursor() cursor.execute('SELECT * FROM "team_season" limit 10')
print (cursor.fetchall())
5、编写程序分析和展示数据
使用flask框架展示数据:
创建一个python文件main.py:
在同级目录下创建 templates 文件夹,编写存放 myindex.html:
运行结果:
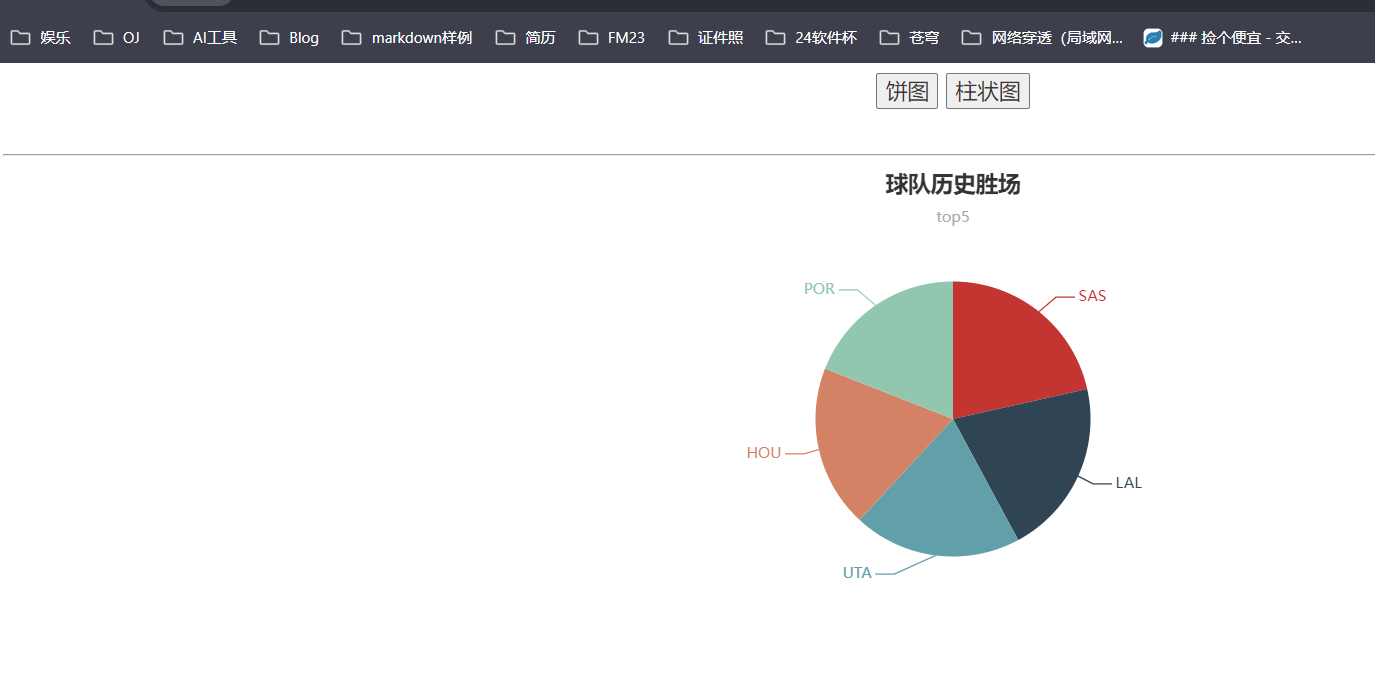
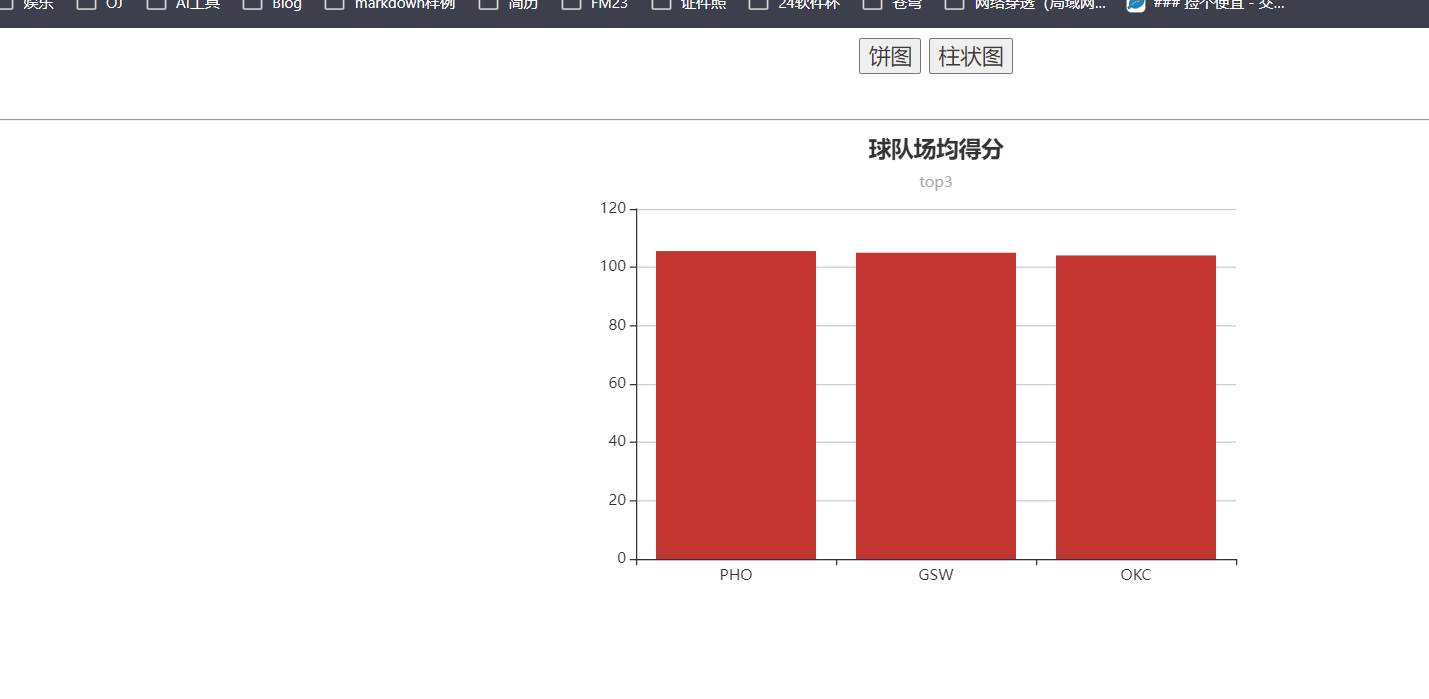
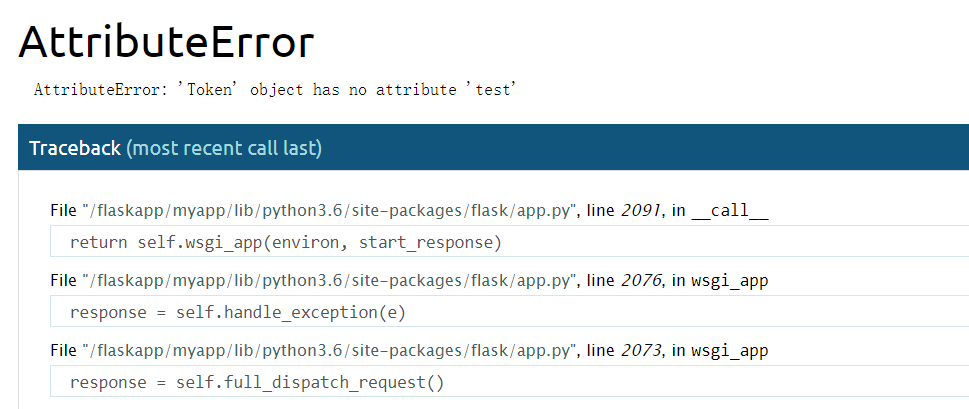
6、总结
flask版本问题、安装virtualenv超时,HMaster进程

四、 大数据流计算系统
0、前言
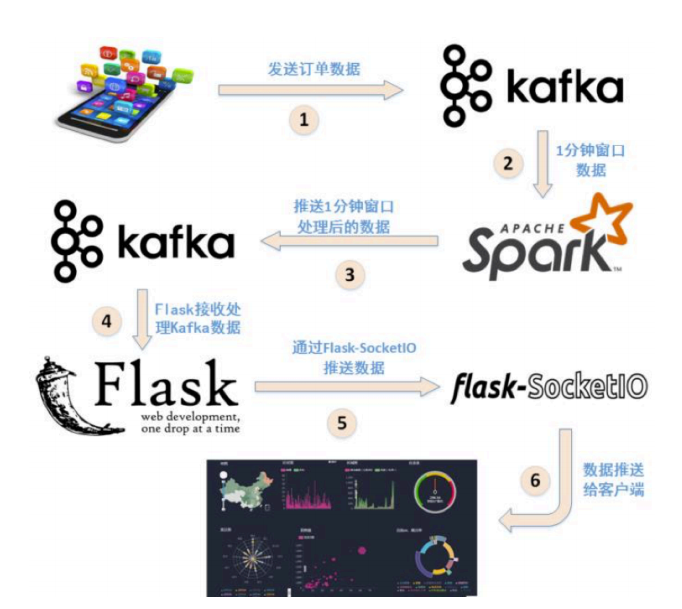
涉及数据预处理、消息队列发送和接收消息、数据实时处理、数据实时推送和实时展示等数据 处理全流程所涉及的各种典型操作, 涵盖 Linux 、Spark 、Kafka 、Flask 、Flask-SocketIO 、Highcharts.js、sockert.io.js、PyCharm 等系统和软件的安装和使用方法。
1、数据处理
数据预处理
上传数据到虚拟机中:
安装相应的python库:

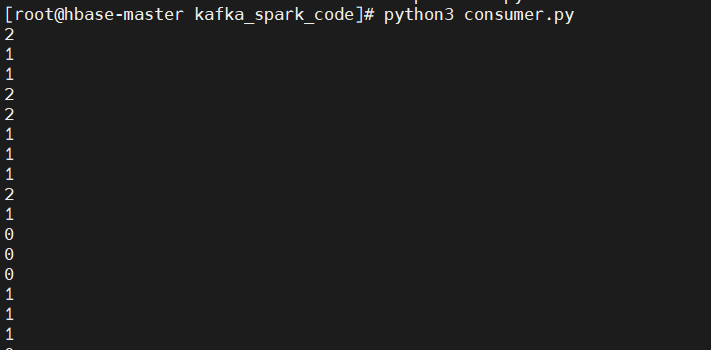
编写kafka代码测试生产者和消费者:

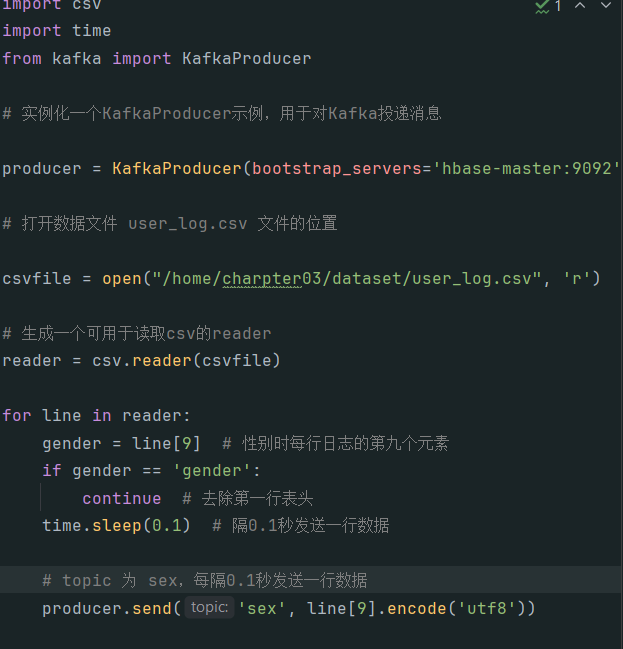
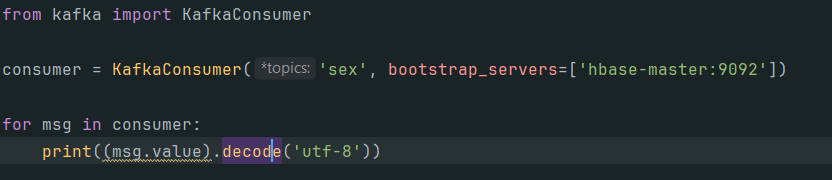
测试结果:

2、scala编程实现实时数据处理
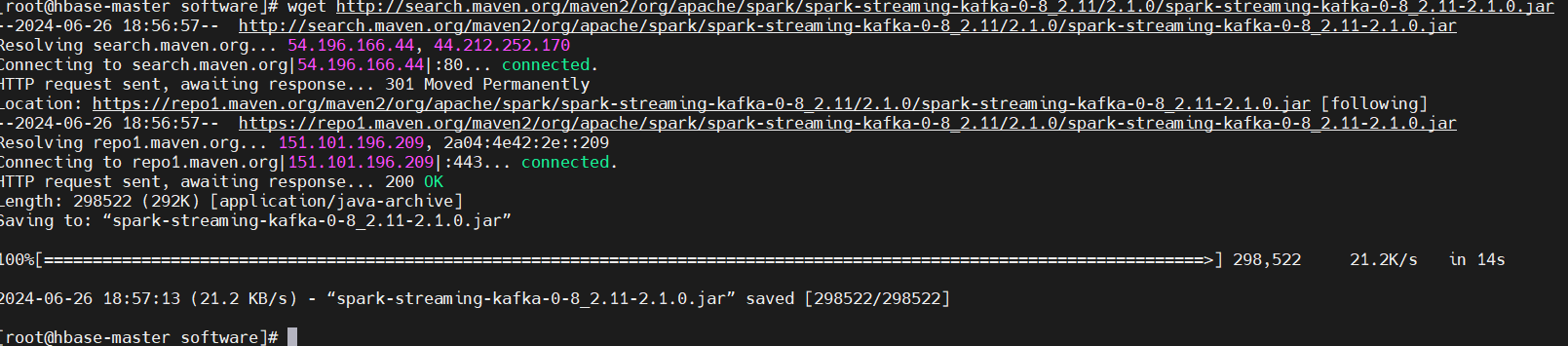
下载spark-streaming-kafka的jar包,并配置环境jar的位置:
1
wget http://search.maven.org/maven2/org/apache/spark/spark-streaming-kafka-0-8_2.11/2.1.0/spark-streaming-kafka-0-8_2.11-2.1.0.jar
在文件夹 kafka_spark_code中建立文件夹 kafka,进入 kafka 文件夹依次建立 src/main/scala 文件存放目录以及 scala 工程文件,项目工程主文件 KafkaTest.scala,设置日志文件为 StreamingExamples.scala:


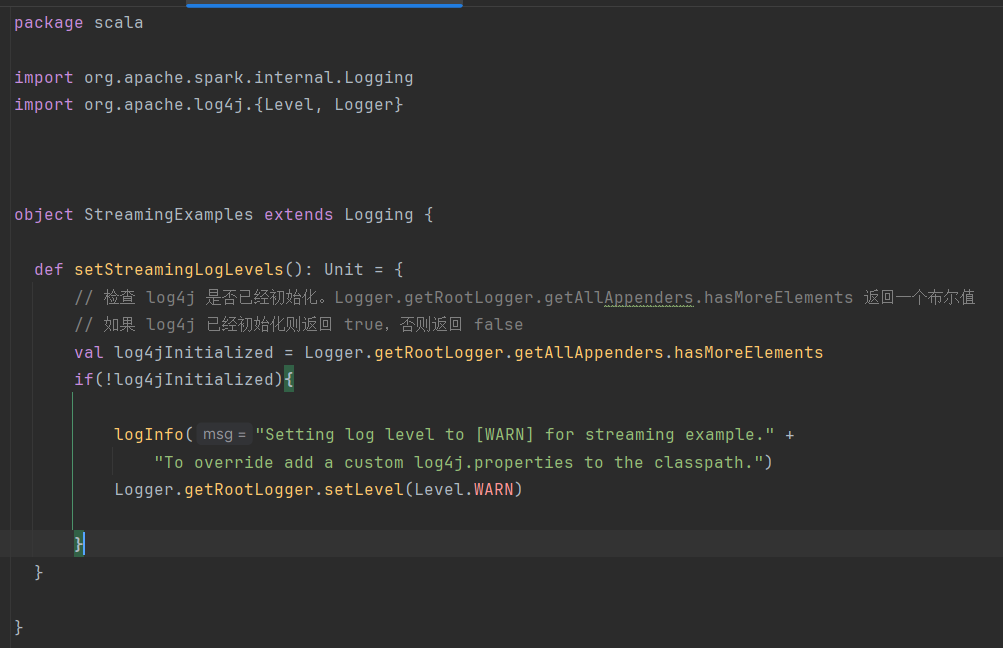
StreamingExamples.scala代码:
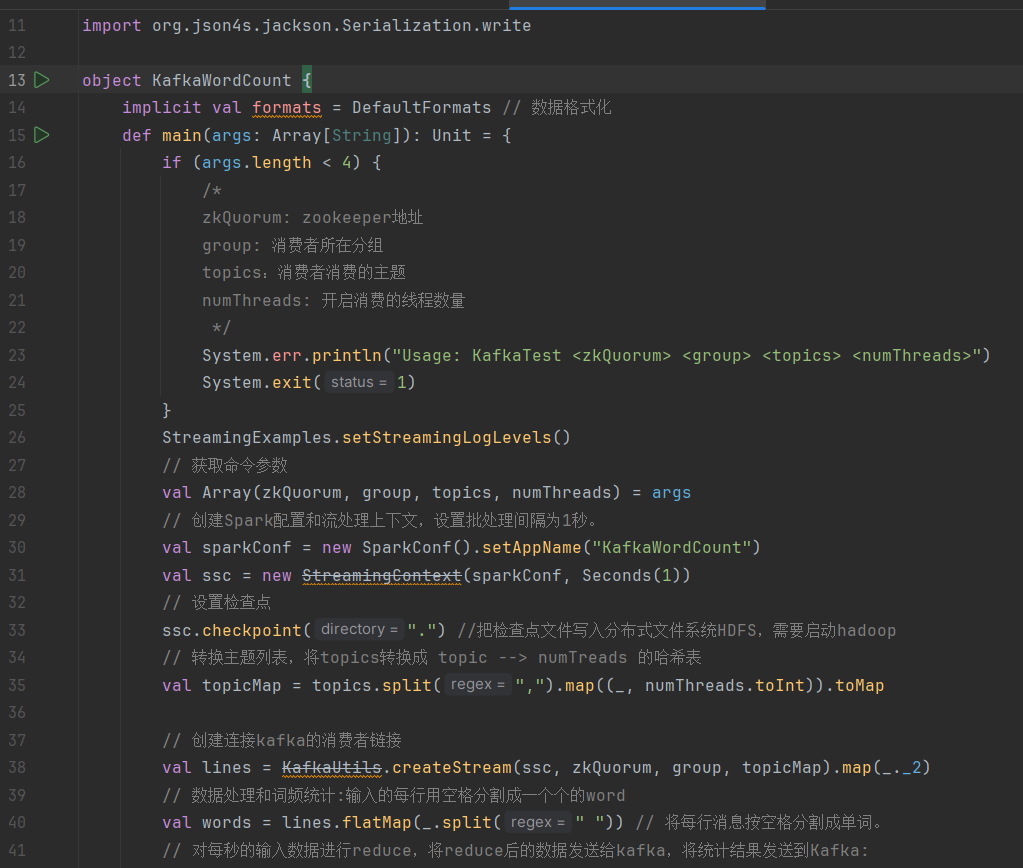
KafkaWordCount.scala程序代码
编写打包配置文件
simple.sbt: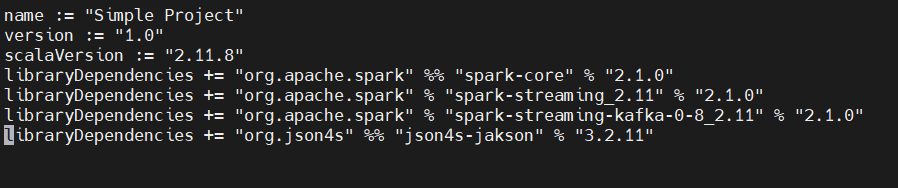
3、运行kafka项目
编译打包程序:
1
/usr/local/sbt/sbt package
编写运行脚本,编写运行脚本,在/usr/local/spark/mycode/kafka 目录下新建 startup.sh 文件,输入以下内容,是一行,并给予脚本执行权限:
1
/root/spark/bin/spark-submit --driver-class-path /root/spark/jars/*:/root/spark/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCount" /home/charpter03/kafka_spark_code/kafka/target/scala-2.11/simple-project_2.11-1.0.jar zoo1:2181 1 sex 1
修改获得运行权限:

测试程序
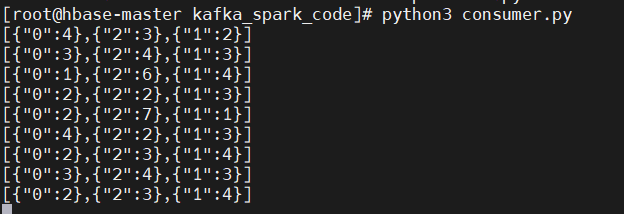
修改consumer.py文件的主题:

启动kafka服务,然后分别运行startup.sh、producer.py、consumer.py文件,查看结果:

4、数据展示处理
利用 Flask 创建 web 程序,利用 Flask-SocketIO 实现实时推送数据,利用 socket.io.js 实现 实时接收数据,hightlights.js 展现数据。
1 | 环境版本: |
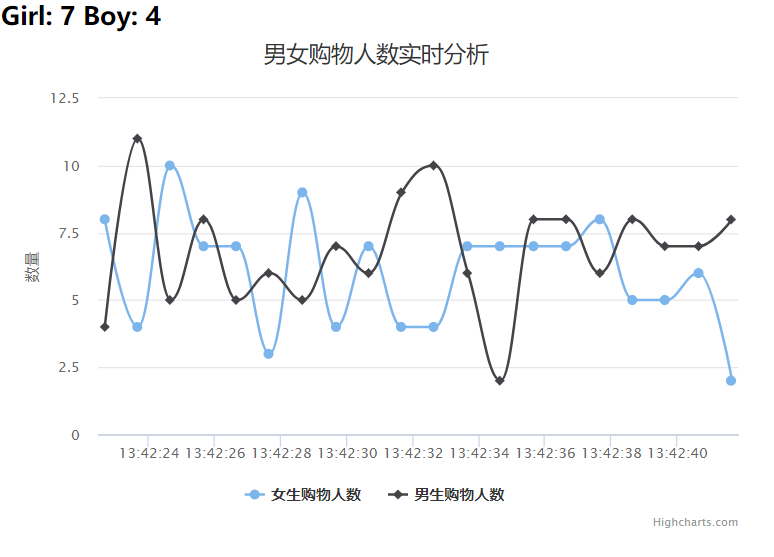
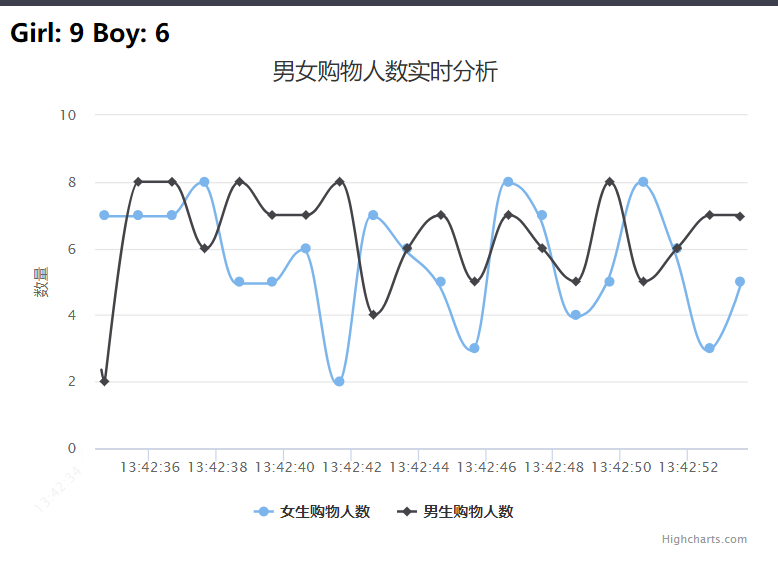
Flask-SocketIO实时推送数据Spark Streaming 实时接收 Kafka 中 topic 为“sex”发送的日志数据,然后 Spark Streaming 进行实时处理,统计好每秒中男女生购物人数之后,将结果发送至 Kafka,topic 为“result”。下面是项目文件层级:
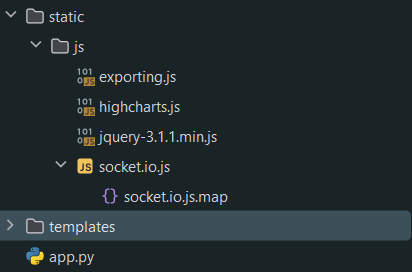
app.py:作为一个简易的服务器,处理连接请求,以 及处理从kafka 接收的数据,并实时推送到浏览器。
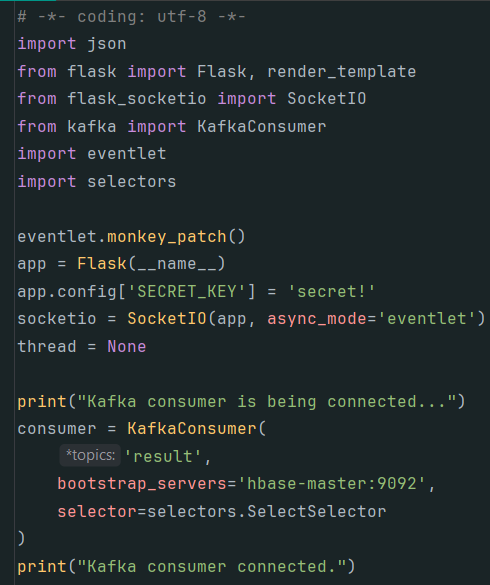
background_thread 函数,该函数从 Kafka 接收消息,并进行处理,获得男女生每秒钟人数,然后将结果通过函数 socketio.emit实时推送至浏览器。
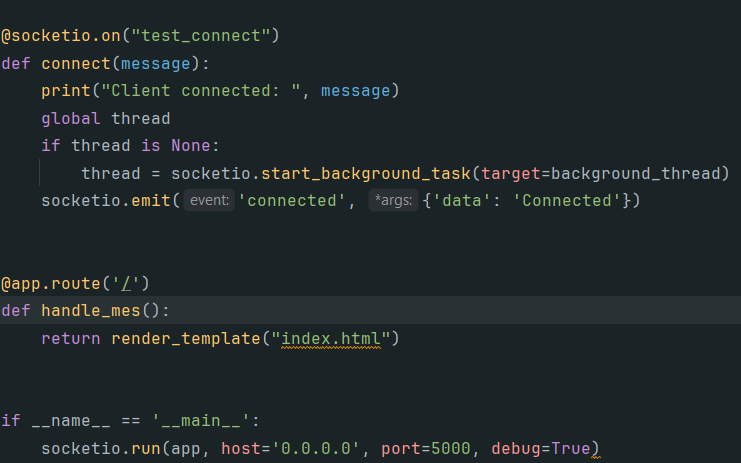
浏览器获取数据并展示
在app.py路径下创建templates/index.html,其负责获取数据并展示效果。
该部分就是使用 socket.io.js 库来实时地接收服务端发送过来的消息,并将消息数据实时地设置在 html 标签内,交给 highcharts.js 进行实时获取和展示。如果出现引擎版本不匹配的错误,可以固定下 python 几个包的版本:
pip3 install Flask-SocketIO==4.3.1
pip3 install python-engineio==3.13.2
pip3 install python-socketio==4.6.0
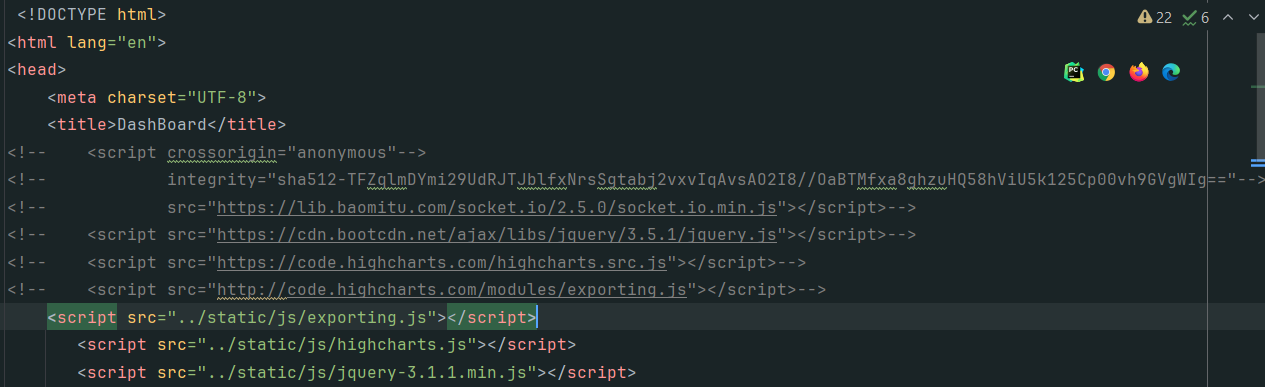
js依赖:
1
2
3
4
5
6><script crossorigin="anonymous"
integrity="sha512-TFZqlmDYmi29UdRJTJblfxNrsSgtabj2vxvIqAvsAO2I8//OaBTMfxa8ghzuHQ58hViU5k125Cp00vh9GVgWIg=="
src="https://lib.baomitu.com/socket.io/2.5.0/socket.io.min.js"></script>
><script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.5.1/jquery.js"></script>
><script src="https://code.highcharts.com/highcharts.src.js"></script>
><script src="http://code.highcharts.com/modules/exporting.js"></script>代码如下
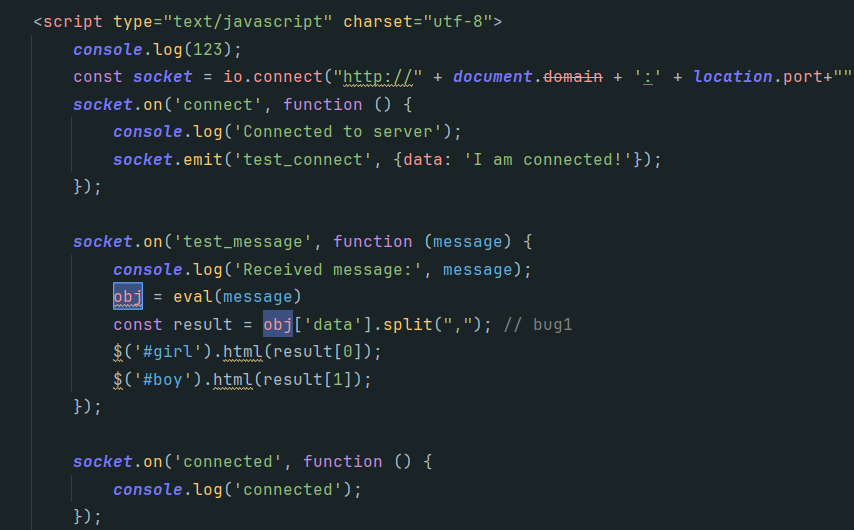
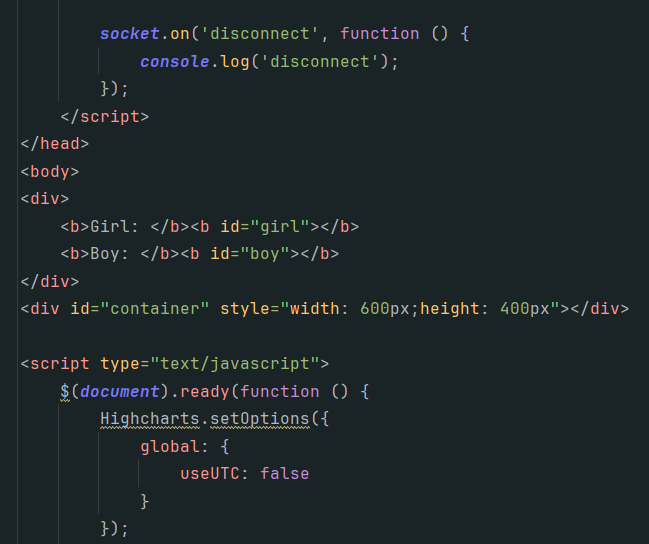
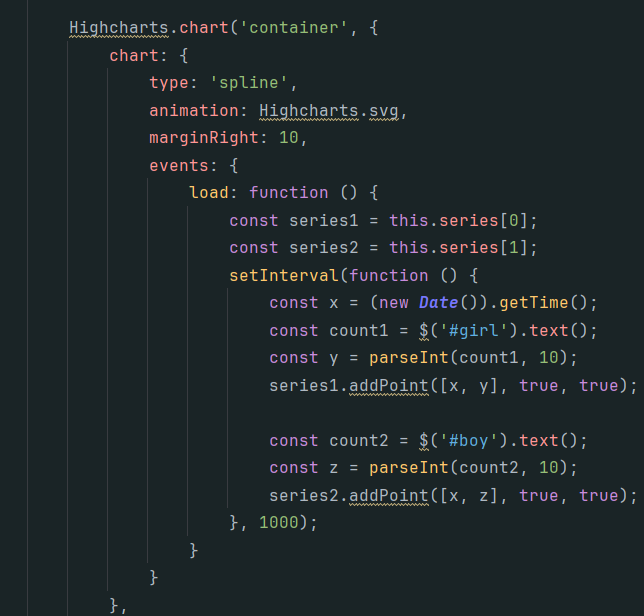
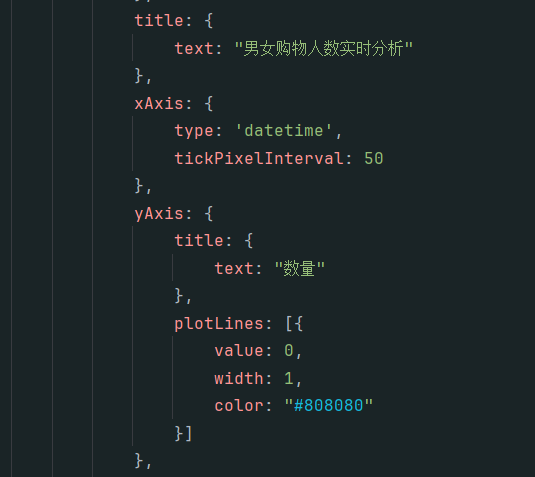
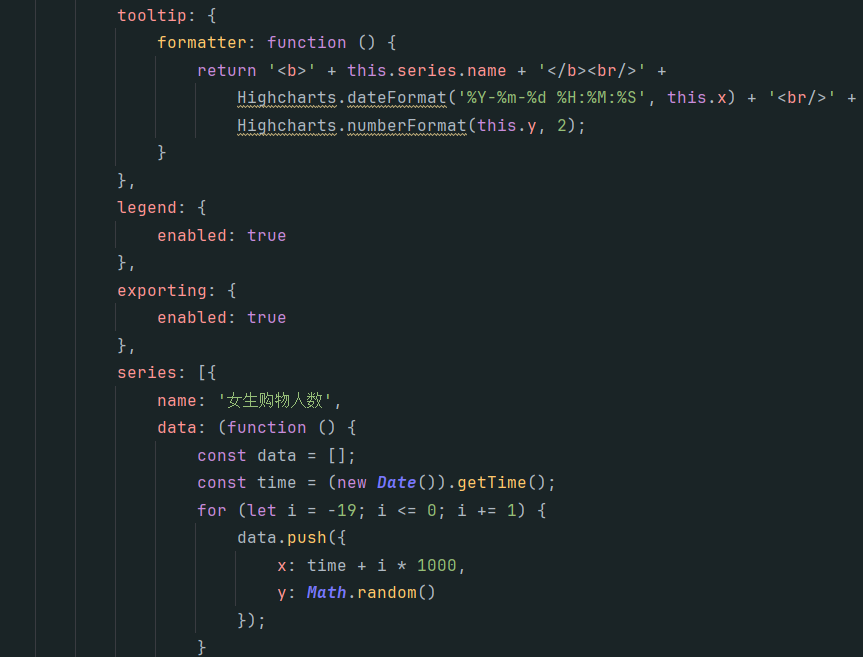
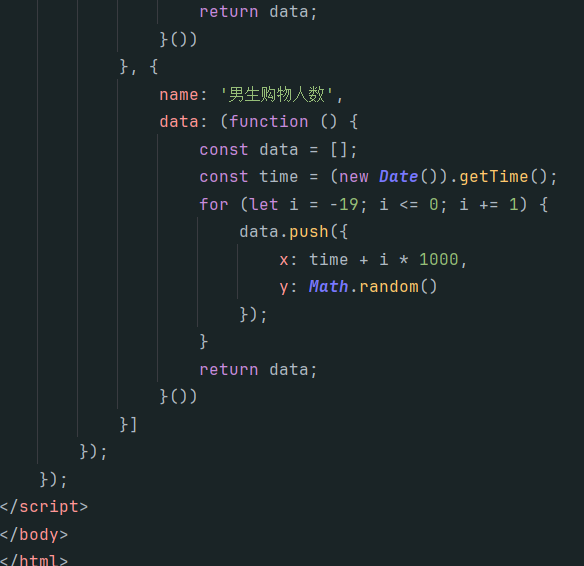
效果展示
启动步骤:
确保 kafka 开启(jps 观察进程是否启动);
开启 producer.py 模拟数据流(python3 producer.py);
启动 Spark Streaming 实时处理数据(scala 版运行 stratup.sh)。
启动 app.py
5、总结
1、主题列表:

2、整个数据的传输过程:
3、socket.io.js,exporting.js版本问题包
4、并发问题
五、大数据图计算系统
0、前言
用 GraphX 分析网络结构,涉及获取数据、解析数据、分析主要主题以及伴生关系、建立伴生网络、理解网络结构、过滤噪声边、计算聚类系数和平均路径长度等数据处理过程,涵盖 Linux、MySQL、Hadoop、HDFS、Spark、Scala、Flask、Python、Echarts 等系统和软件的应用。
1、获取实验数据
注:原始数据量较多,但由于本实验镜像虚拟的分布式集群内存只有 7.5G,启动Hadoop 平台就要占用大量内存资源,该实验最后一部分计算节点之间的平均路径需要消耗非常多的内存资源,不足以计算出结果,考虑到单机现有的内存条件,所以本实验采取相对合适节点数量的数据集,数据量为 480,足以完成整个实验流程及学习内容的要求。
1、先将数据通过MobaXterm上传到虚拟机中,然后通过命令docker cp /tmp/dataset/chapter04/. hbase-master:/home/chapter04/dataset/上传到hbase-master节点上:

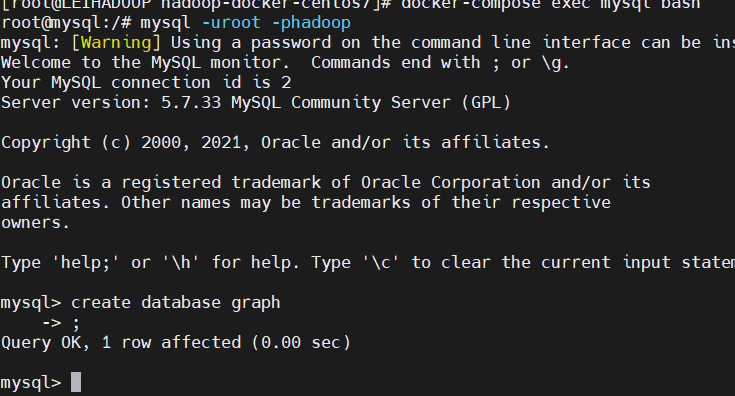
2、创建数据库 graph,为后面可视化展示做准备:
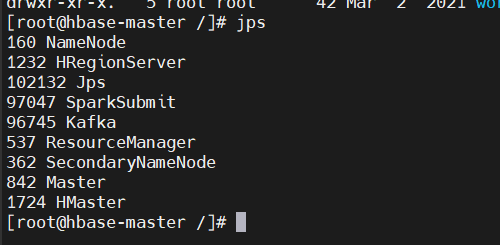
3、查看 namenode,datanode 是否正常启动,HRegionServer 跟 hbase 相关,没有的话直接启动:
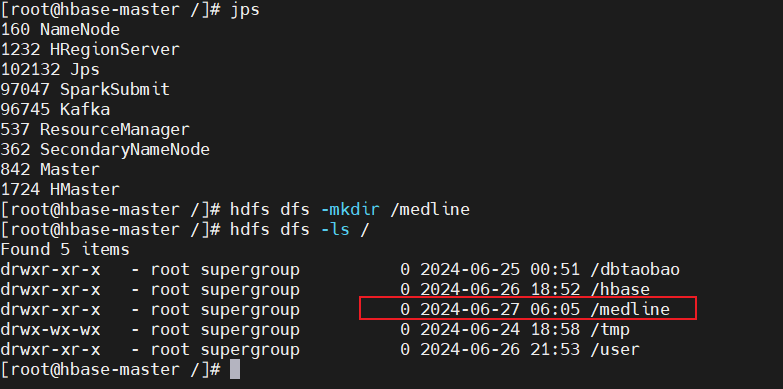
4、在hdfs创建medline文件夹,并将medsamp2016a.xml加载到该文件夹下:
1 | hdfs dfs -mkdir /medline |
5、spark-shell --jars ch07-graph-2.0.0-jar-with-dependencies.jar启动spark:
6、把 xml 格式的 medline 数据读到 Spark shell 中:
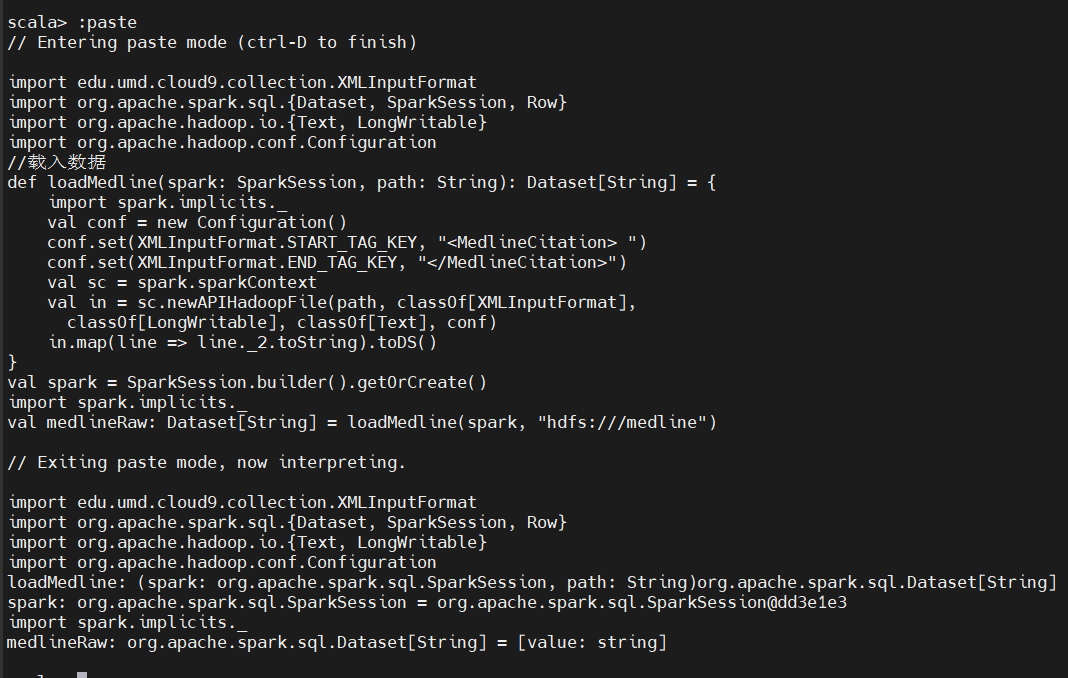
7、用 Scala XML 工具解析 XML 文档,变量elem 是scala.xml.Elem 类的实例,Scala 用scala.xml.Elem 类表示XML 文档中的一个节点,该类内置了查询节点信息和节点内容的函数。Cache函将解析结果缓存起来:
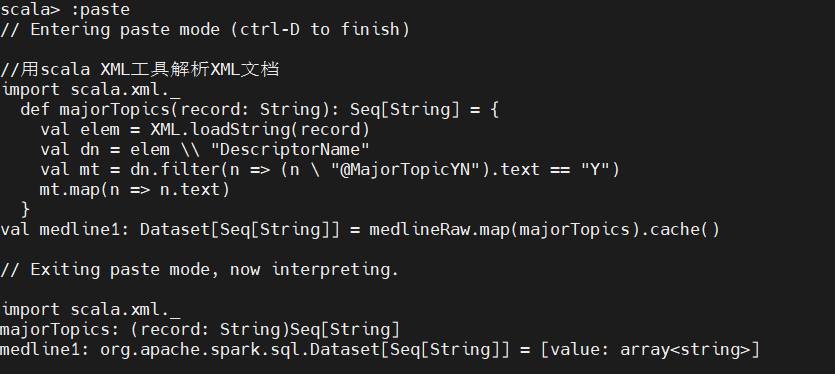
2、分析网络主要主题及其伴生关系
FlatMap 获取数据集标签后,我们需要知道数据集中标签的总体分布情况,为此我们需要使用 SparkSQL 计算一些基本统计量,比如记录条数和主要主题出现频率的直方图,并将统计结果保存到 mysql,用于可视化展示:
记录下登录时的 ip:

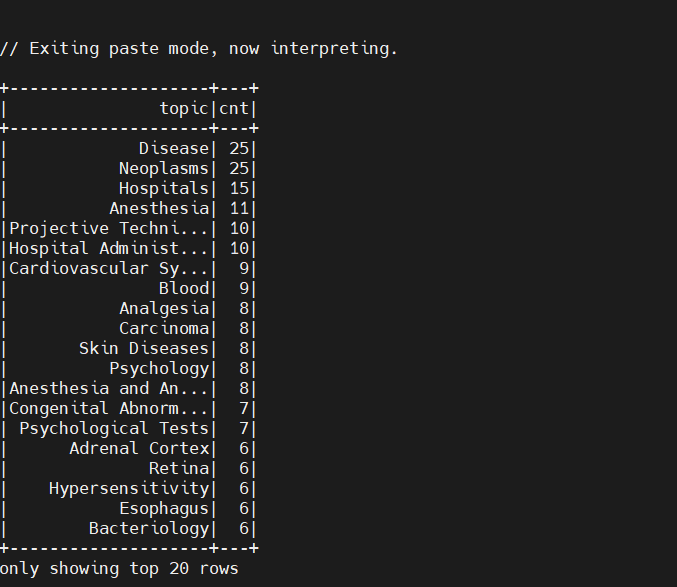
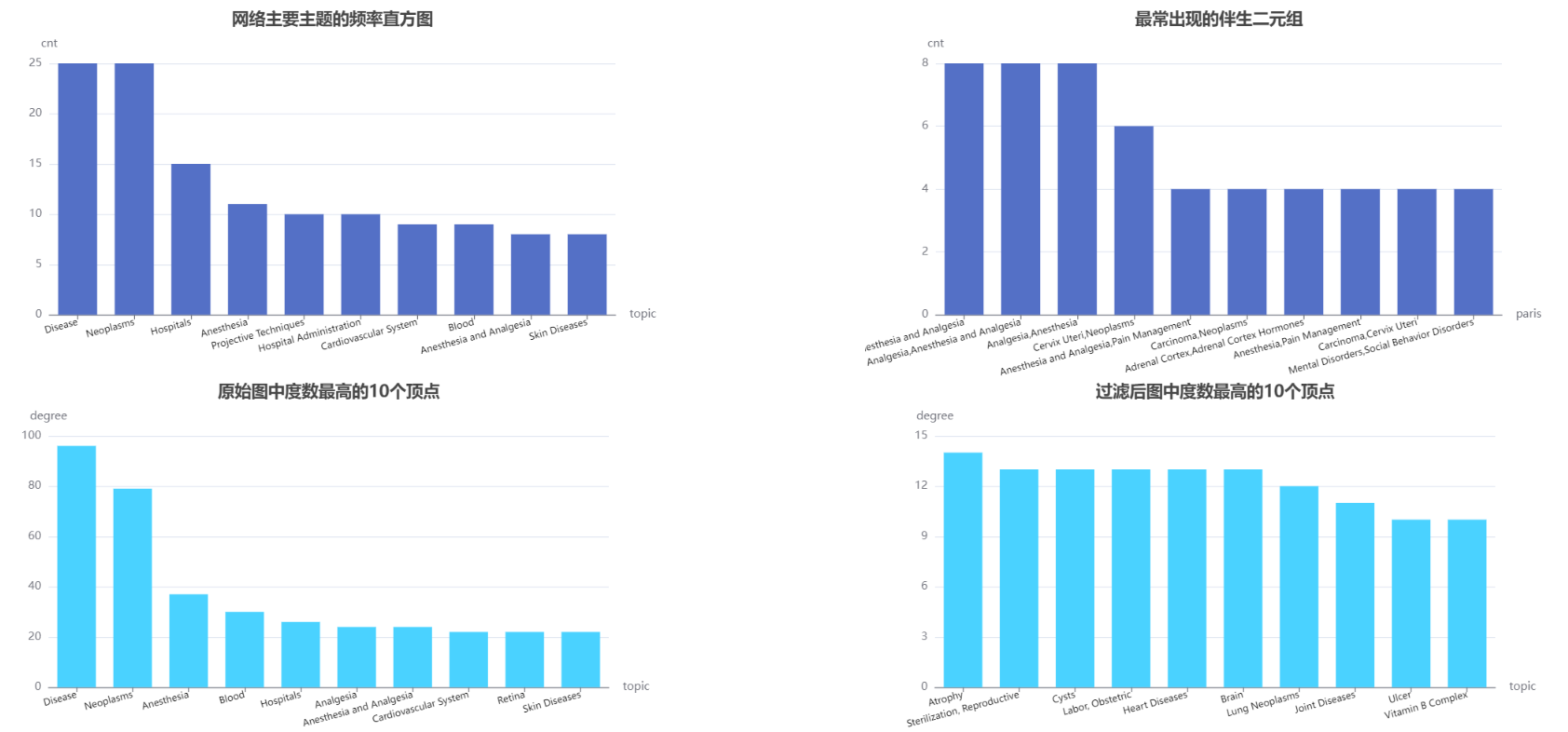
上面的数据给出了一个大致的描述,包括一共有多少个主题,最频繁的主题等。可以看到,我们的数据一共有 480 个文档,最频繁出现的 topic(Disease)只占了很少一部分(25/480= 5%)。对此,我们猜测包含某个主题的文档的个数的总体分布可能为长尾形态:
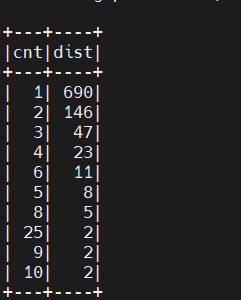
要得到伴生关系,我们要为这些字符串列表生成一个二元组集合。对此我们可以使用 Scala 集合工具包里的 combinations 方法,它返回的是一个 Iterator:
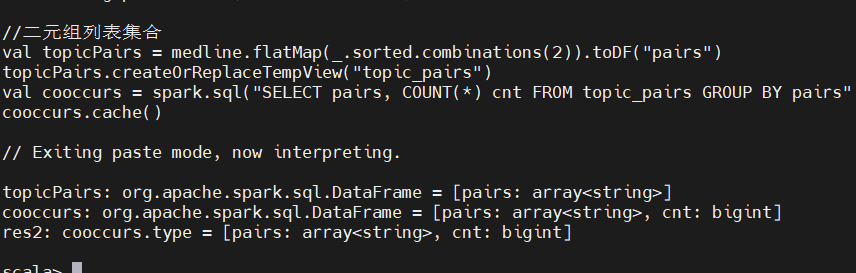
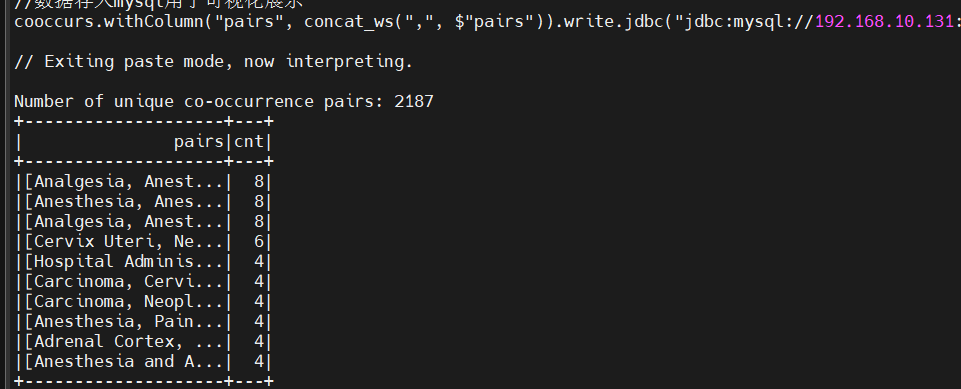
查看一下数据中最常出现的伴生二元组,将数据存入 mysql:
以上并未提供特别有用的信息,最常见的伴生二元组与最常见的topic非常相关。除此之外,也没有提供什么额外的信息。
3、用 GraphX 来建立一个伴生网络
实验的核心在于把伴生网络当作网络来分析:把主题当作图的顶点,把连接两个主题的引用记录看成两个相应顶点之间的边。这样就可以计算以网络为中心的统计量。GraphX 构建与 Spark 之上,它继承了 Spark 在可扩展性方面的所有特性,这就意味着可以利用 GraphX 对规模极其庞大的图进行分析。
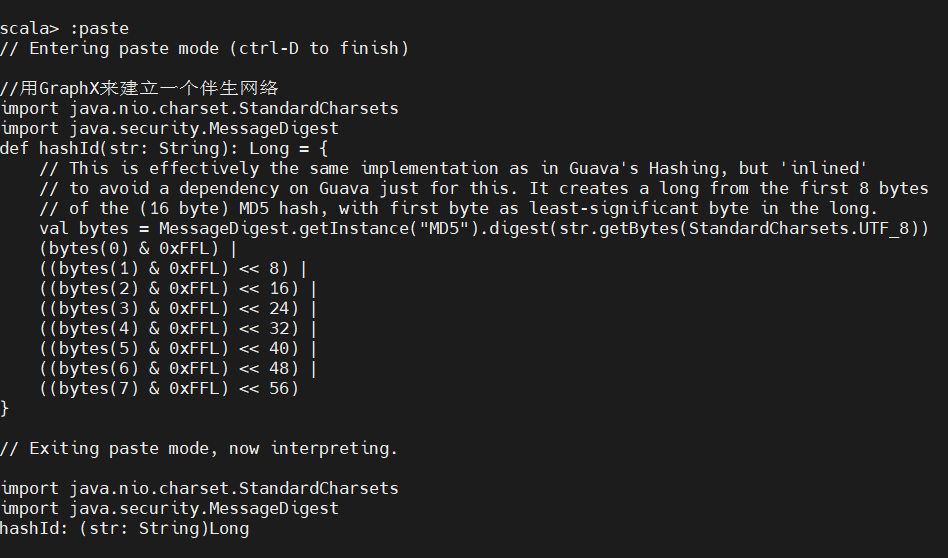
在Medline数据上运行该散列函数可以得到一个DataFrame,以它为基础就可以得到伴生关系图的顶点集合:

用前一节中得到的伴生频率计数来生成图的边,方法是使用hash 函数将每个主题映射到相应的顶点ID:
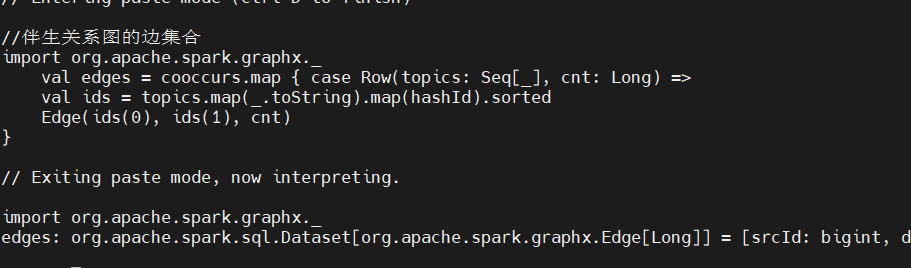
把顶点和边都创建好后,就可以创建Graph 实例了。我们需要将Graph 缓存起来,这样便于后续处理时使用:
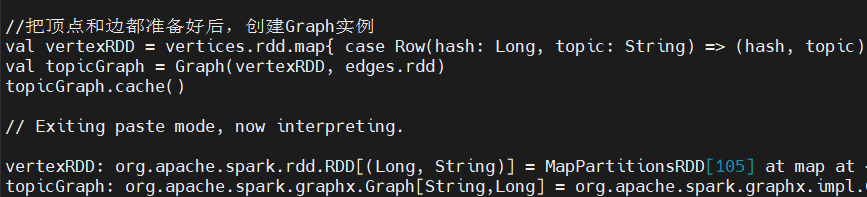
4、理解网络结构
1、连通组件
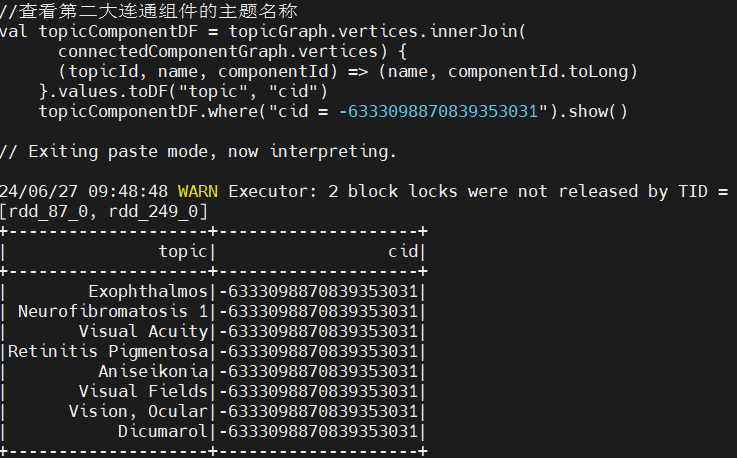
最基本的属性之一就是是否是连通图。如果图是非连通的,那么可以将图划分成一组更小的子图,这样就可以分别对每个子图进行研究。连通性是图的基本属性,通过调用 GraphX 的 connectedComponents 方法获取:
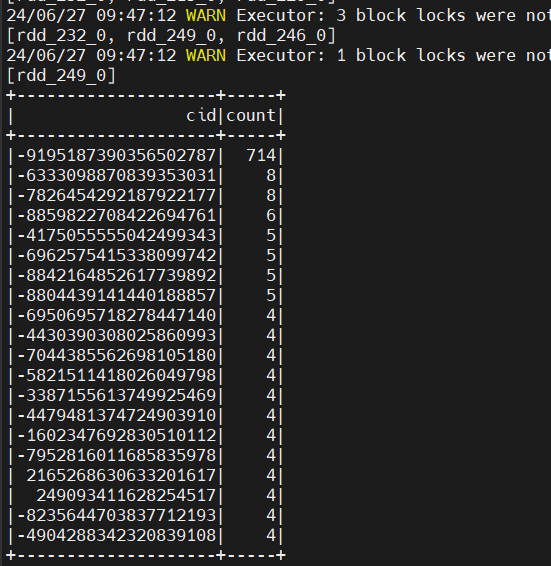
大连通组件的主题名称:
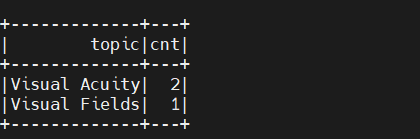
查看最初的主题分布,是否有类似 Visual 的主题:
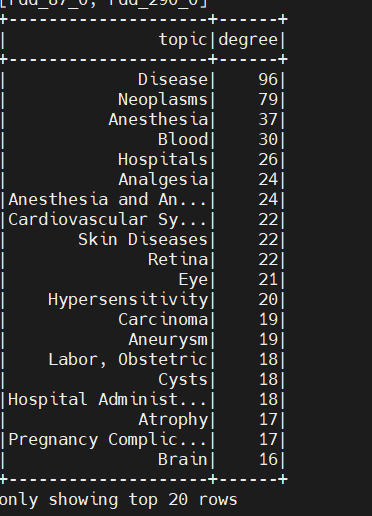
2、度的分布
为了更多了解图的结构信息,我们需要知道每个顶点的度,也就是每个顶点所属边的条数。GraphX 中我们可以通过在 Graph 对象上调用 degrees 方法得到每个顶点的度。degrees 方法返回一个整数的 VertexRDD,其中每个整数代表一个顶点的度。现在我们计算一下图的度,然后可以查看到度数较高的主题,并将数据存入 mysql:
5、过滤噪声边
在当前的伴生关系中,边的权重是基于一对概念同时出现在一篇论文中的频率来计算的。这种简单的权重机制的问题在于:它并没有对一对概念同时出现的原因加以区分,有时一对概念同时出现是由于它们具有某种值得我们关注的语义关系,但有时一对概念同时出现只是因为都频繁地出现在所有文档中,同时出现只是碰巧而已,因此需要对噪声边进行处理,这里采用卡方准则。
1、处理 EdgeTriplet
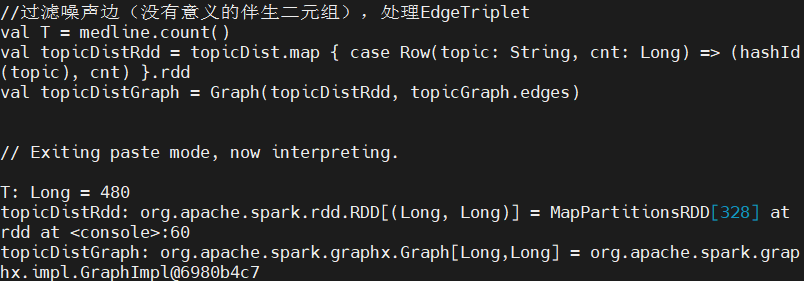
计算卡方统计量,需要组合顶点数据(比如每个概念在一个文档中出现的次数)和边数据(比如两个概念同时出现在一个文档中的次数):
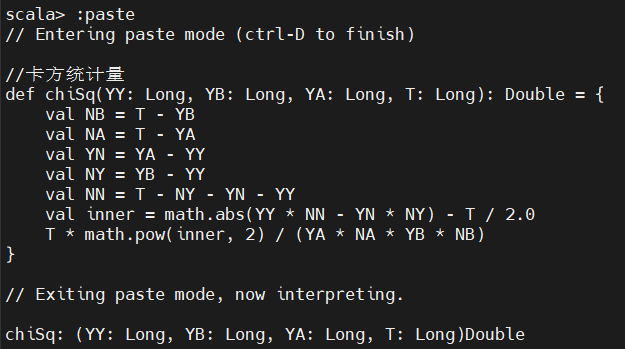
用该方法通过 mapTriplets 算子转换边的值。mapTriplets 算子返回一个新图,这个图的边的属性就是每个伴生对的卡方统计量。于是我们就可以大概知道该统计量在所有边上的分布情况:
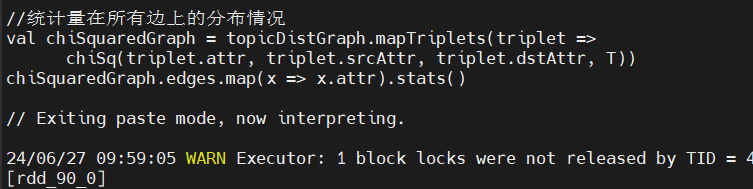

使用 19.5 作为阈值,这样过滤后图中就只剩下那些置信度非常高的有意义的伴生关系。我们将在图上利用 subgraph 方法进行过滤,这个方法接受 EdgeTriplet 的一个布尔函数,用以判断子图应该包含哪些边:
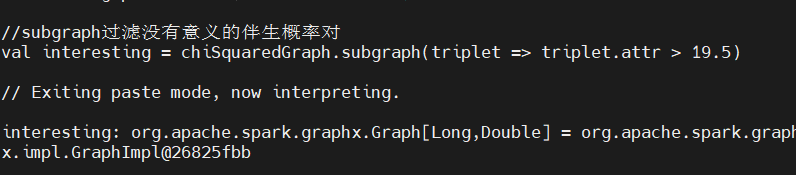
2、分析去掉噪声边的子图
在过滤后的子图上运行连通性算法,检查组件个数和组件大小:
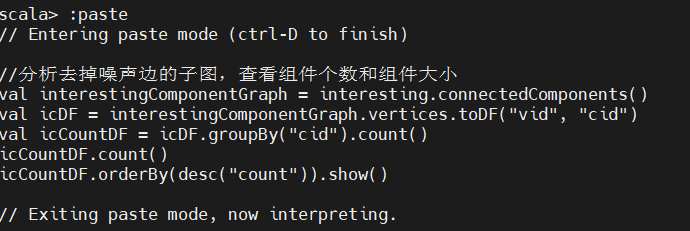
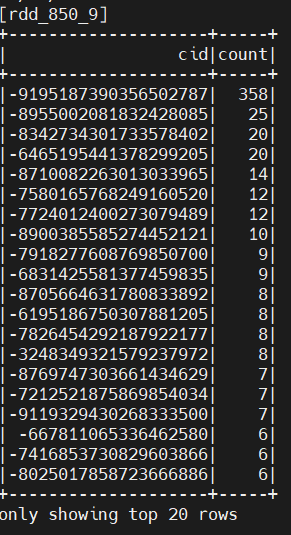
发现连通组件总数发生改变,且最大连通组件也被瓦解,说明该数据集有较多的噪声干扰。如果数据量较多,将会对最大连通组件产生较小的影响。检查一下过滤后的度分布:

看到过滤后平均值变小了,主要主题也产生变化,原因是数据集样本的噪声比较多。我们看一下过滤之后概念和度的关系:
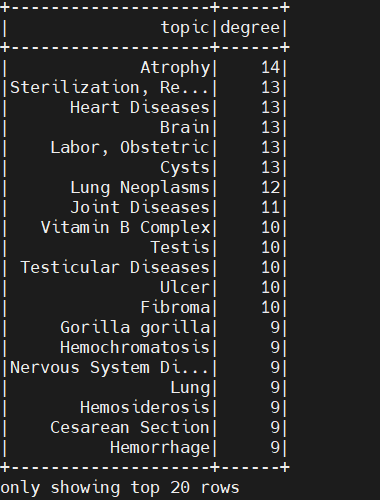
结果表明虽说这次卡方过滤准则不太理想,问题在于使用数据集样本太小,如果用原始数据集,将会产生较好的结果;但是它在清楚对应普遍概念的边的同时,保留了代表概念之间有意义并且有值得注意的关系的那些边。
6、系和聚类系数
如果每个顶点都存在一条边与其他任何节点都相连,那这个图就是个完全图。给定一个图,可能有多个子图是完全图,我们可以将这些子图称为系,如果途中存在这种许多大型的系,表示这个图具有某种局部稠密结构。
三角形是一个完成图,顶点 V 的三角计数就是包含该顶点的三角形个数。三角计数度量了 V 有多少个邻接点是相互连接的。Watts 和 Strogatz 定义了一个新的指标,称为局部聚类系数,它是一个顶点的实际三角计数与其邻接点可能的三角级数的比率。对无向图来说,有 k 个邻接点和 t 个三角计数的顶点,其局部聚类系数 C 为:
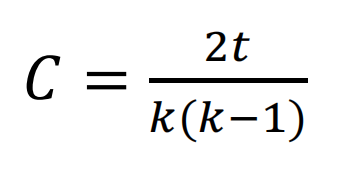
用GraphX 来计算过滤后的概念图的每个节点的局部聚类系数。GraphX 有个内置方法triangleCount,它返回一个Graph 对象,其中VertexRDD 包含了每个顶点的三角计数。然后对所有顶点局部聚类系数取平均值,就得到网络平均聚类系数:


7、平均路径长度
用Pregel求两个节点之间的最短路径,这里我们会计算过滤之后的概念图中的大型连通组件节点的平均路径长度。计算图中顶点之间的路径长度是一个迭代过程,和我们之前寻找连通组件的迭代过程类似:每个阶段,每个顶点将保留它所接触过的顶点列表并记录到这些顶点的距离。接着每个顶点都向其邻接点查询它对应的节点列表,如果发现该列表中有新的顶点,就用新节点更新自己的节点列表;查询邻接点并更新自己节点列表的过程一直继续下去,直到所有节点都没有发现有新节点需要添加为止。
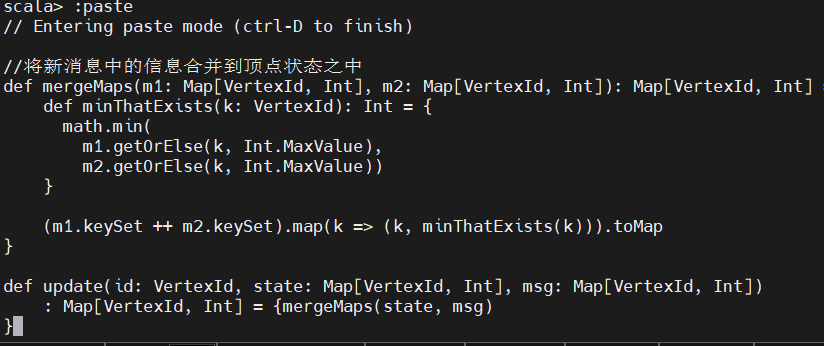
确定了顶点状态和消息内容的数据结构后,我们可以实现两个函数。第一个函数是 mergeMaps,用于将新消息中的信息合并到顶点状态之中。对我们讨论的问题来说,顶点状态和消息都是 Map[VertexId, Int] 类型的,因此需要把两个 map 中的内容合并在一起并将每个 VertexId 关联到两个 map 中该 VertexId 对应两个条目的最小值。

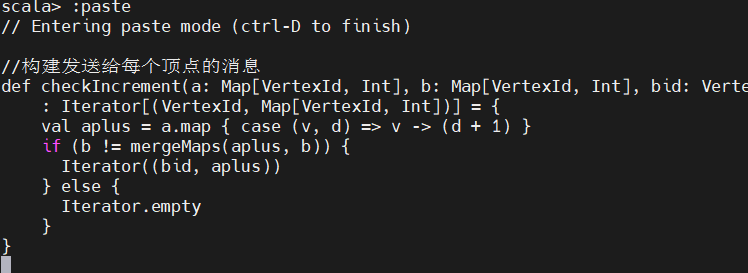
最后编写代码来构建发送给每个顶点的消息,依据是每次迭代是每个顶点从邻接点收到的消息:

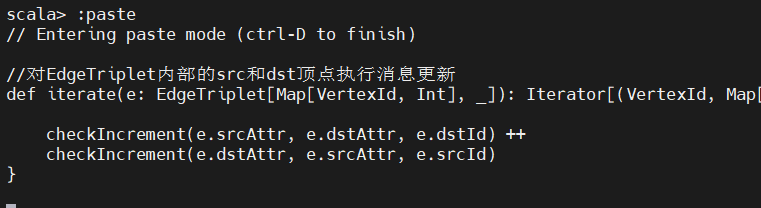
在每个Pregel迭代过程中,对EdgeTriplet内部的src和dst顶点执行消息更新:
如果一次迭代中有任何顶点没收到消息,pregel’算法认为该顶点的运算已经完成并不再把它放在后续处理中。计算任意两个顶点之间的路径长度,使用 RDD 的sample 方法对所有 Vertexid 进行 2%的不重复采样,随机数生成器的随机种子采用 1729L:
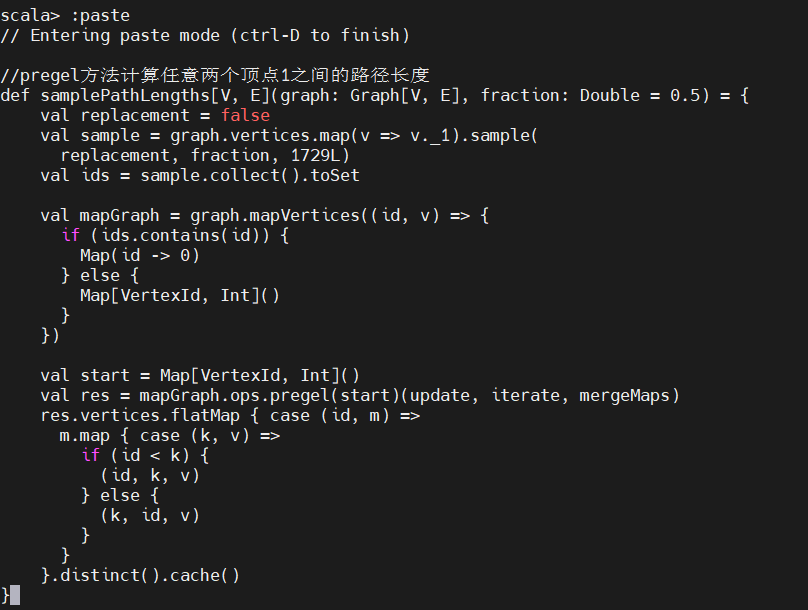

计算样本路径长度直方图:

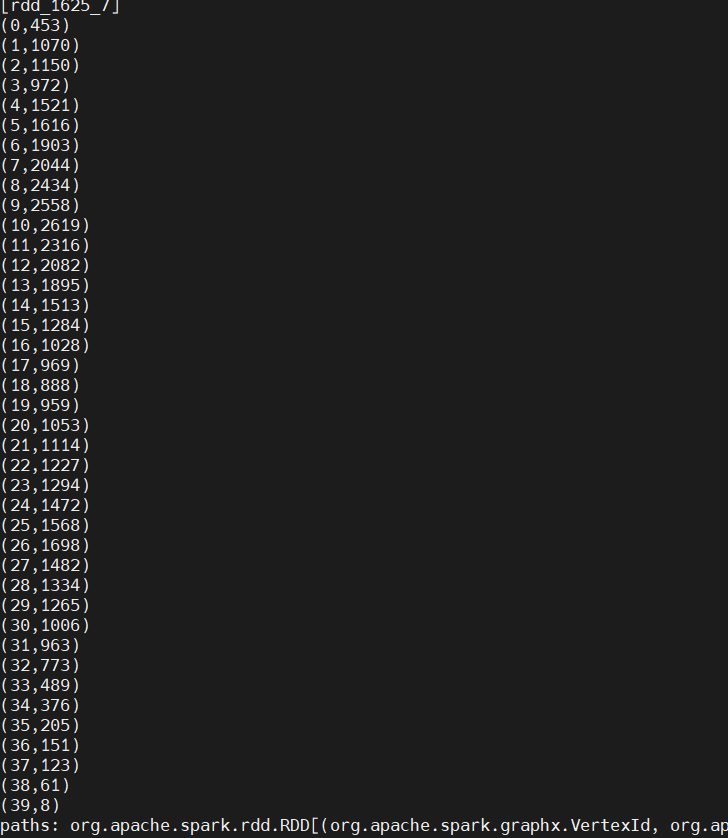

看到,样本的平均路径长度为 15.7,聚类系数为 0.625。
8、Echarts可视化展示
1、登录MySQL,查看mysql中是否有相关数据库和表:
2、数据可视化展示
结果展示:
使用flask框架搭建前端展示页面,文件目录结构:
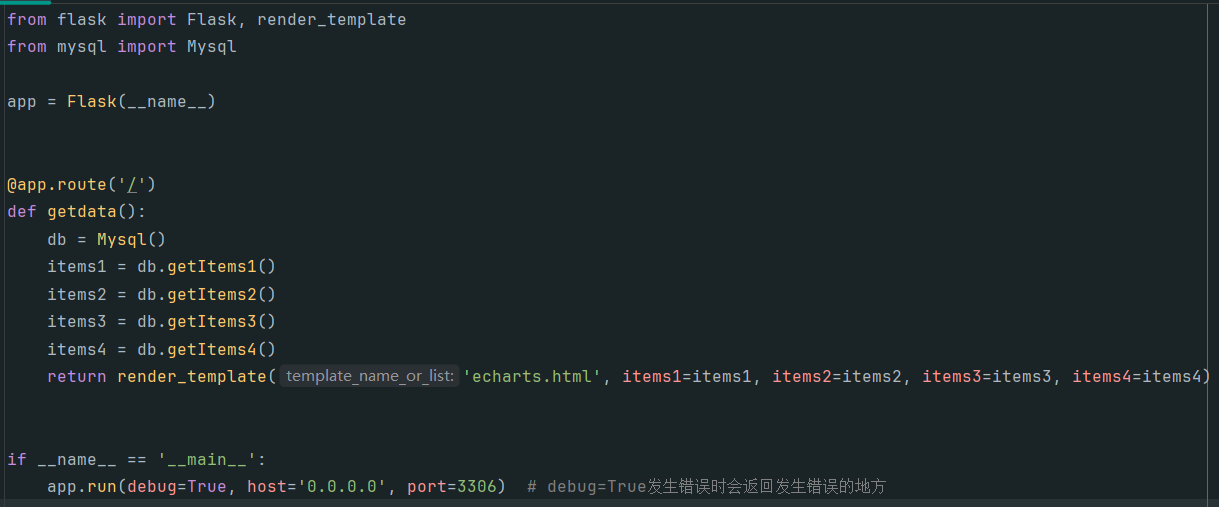
app.py:
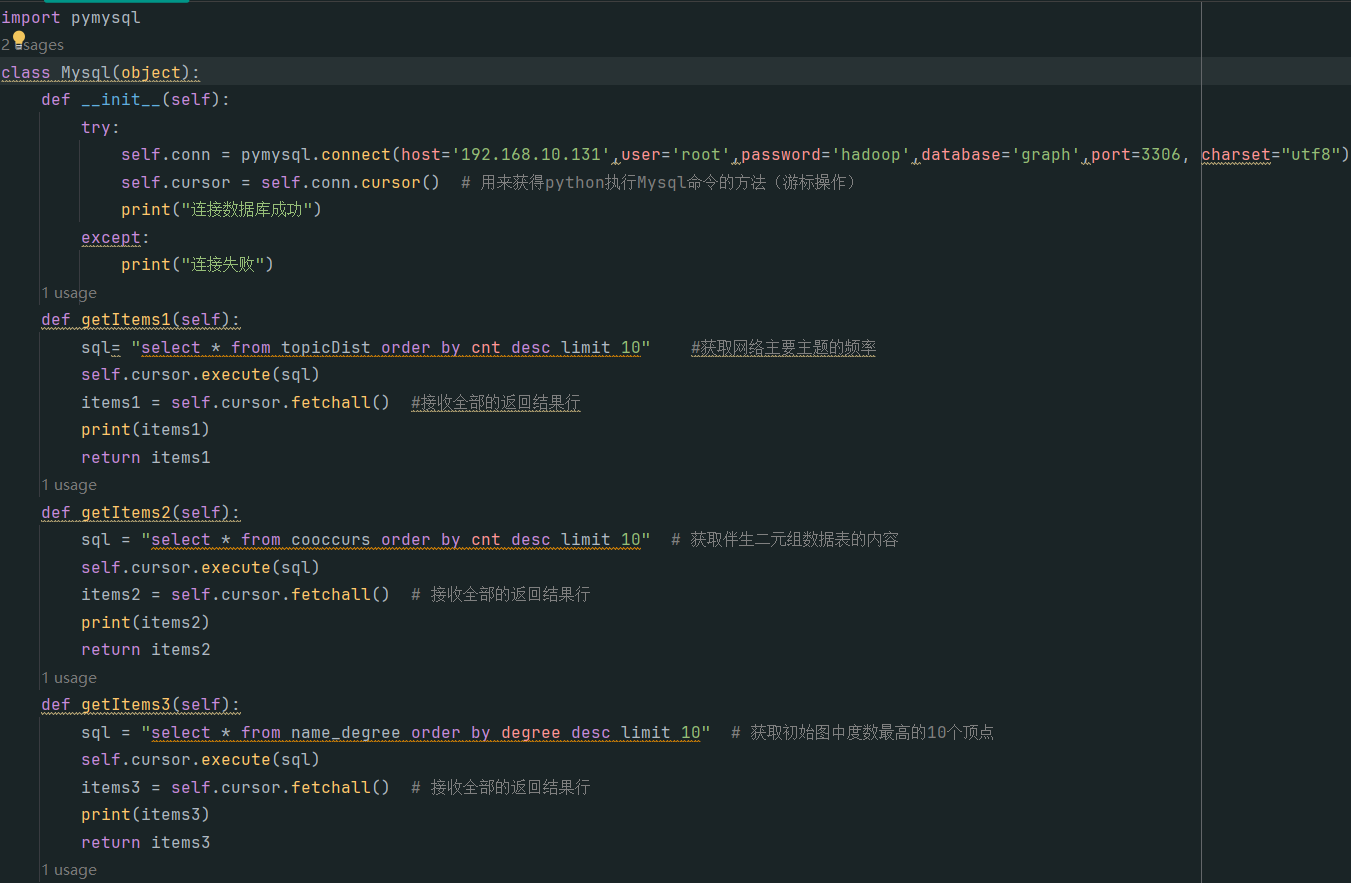
mysql.py:

echarts.html代码: