





在深度学习中,梯度消失和梯度爆炸是训练深层神经网络时常见的挑战。要真正理解这些问题,必须深入理解反向传播的机制,尤其是梯度是如何通过链式法则逐层传播的。本文通过手推反向传播的数学推导,帮助理解梯度消失和梯度爆炸的根本原因。
在深度学习中,梯度消失和梯度爆炸是训练深层神经网络时常见的挑战。要真正理解这些问题,必须深入理解反向传播的机制,尤其是梯度是如何通过链式法则逐层传播的。本文通过手推反向传播的数学推导,帮助读者理解梯度消失和梯度爆炸的根本原因。
准备工作
在开始反向传播的推导之前,我们需要明确网络的结构和损失函数的定义。假设我们有一个简单的神经网络,包含两个输入、两个隐藏层神经元和两个输出神经元。每个神经元的输出通过
sigmoid函数进行激活,损失函数为均方误差。
每个神经元:
其中
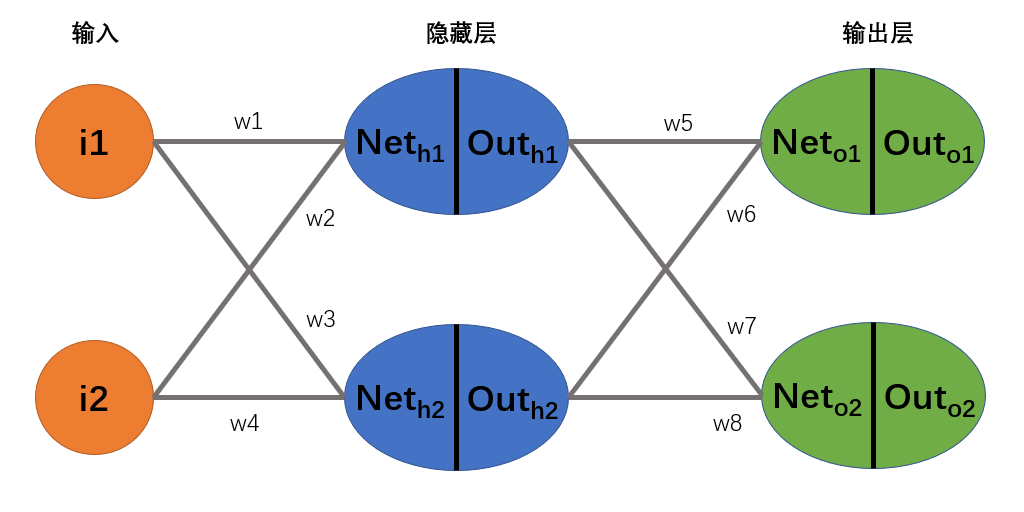
损失函数:
反向传播
反向传播是神经网络训练的核心算法,它通过链式法则计算每一层的梯度,并根据梯度更新网络参数。为了理解梯度消失和梯度爆炸问题,我们需要详细推导反向传播的过程。首先,我们从输出层的参数
w5开始,逐步推导每一层的梯度。
对参数
其中:
故
对参数
对于加号左部分各偏导:
故:
同理计算可得加号右边部分:
最终得到
分析
通过手推反向传播的数学推导,我们可以清晰地看到梯度是如何通过链式法则逐层传播的。接下来,我们将分析这些推导结果,探讨梯度消失和梯度爆炸问题的根本原因。
经过手推反向传播的数学推导,我们得到了一个较为复杂的表达式。尽管这只是针对一个简单的网络结构(仅包含一个隐藏层的两个神经元和两个输出神经元)中某个参数更新的计算过程,但其复杂性已经显而易见。为了简化式子,我们将
对于我们只有一个隐藏层两个神经元的网络,就已经得到了如此复杂的式子,且其中的乘法运算比较多,然而我们普遍的神经网络结构为如下图所示:
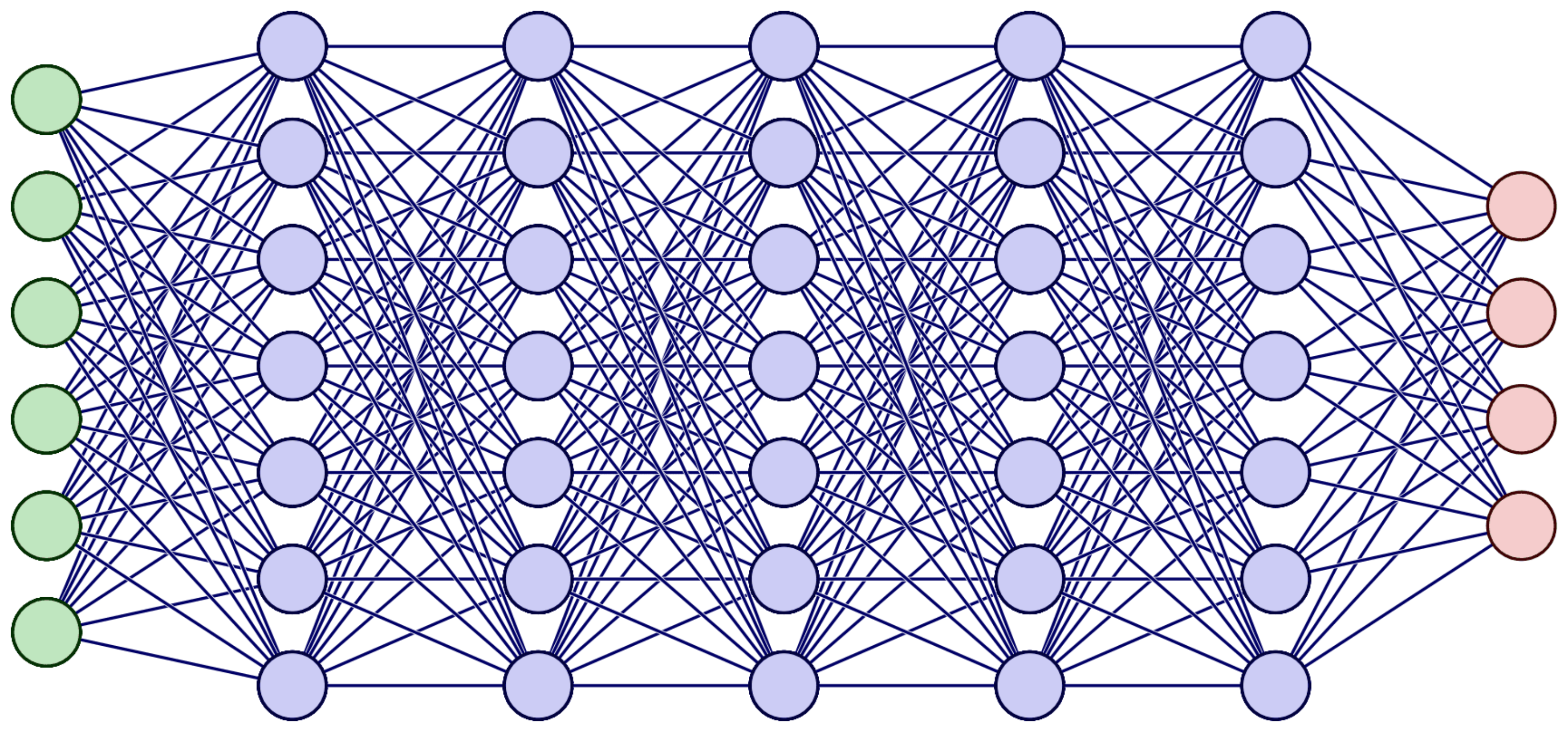
其中的计算复杂度不敢想象。。。
梯度消失问题
梯度消失问题是深层神经网络训练中的常见挑战之一。它主要表现为在反向传播过程中,梯度随着层数的增加而逐渐变小,最终导致参数更新缓慢甚至停止。为了理解梯度消失问题的根源,我们从激活函数的导数
sigmoid入手,分析梯度是如何在传播过程中衰减的。
梯度消失问题的主要原因在于激活函数的导数。以sigmoid函数为例,如下图其导数的最大值为0.25,这意味着在反向传播过程中,梯度会随着层数的增加而不断衰减。具体来说,每一层的梯度都会乘以一个小于1的值,导致梯度在传播过程中逐渐变小,最终接近于零。这种情况下,网络的参数更新会变得非常缓慢,甚至停止更新,导致模型无法有效学习。
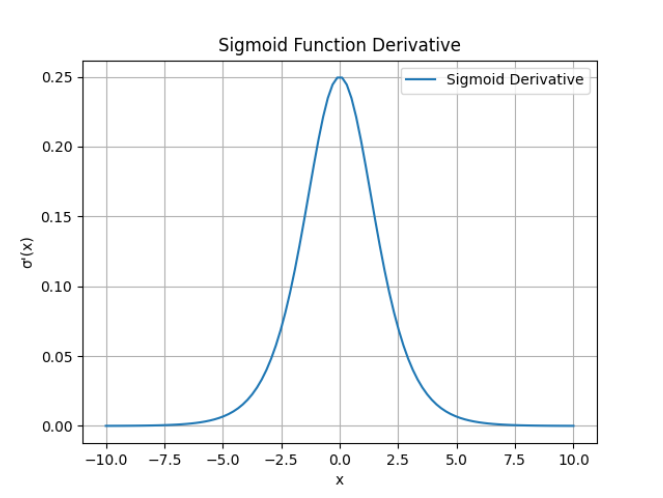
为了更直观地理解梯度消失问题,我们可以考虑一个深度神经网络。假设网络有L层,每一层的梯度都会乘以sigmoid函数的导数。由于sigmoid函数的导数小于
梯度爆炸问题
在反向传播过程中,梯度是通过链式法则逐层传播的。每一层的梯度都会乘以该层的权重矩阵。如果这些权重的初始值过大,梯度在传播过程中会不断放大。具体来说,假设某一层的权重矩阵为 W,其值较大,那么在反向传播时,梯度会乘以 W,导致梯度值迅速增大。随着网络层数的增加,这种放大效应会累积,最终导致梯度爆炸。
例如,假设每一层的梯度都乘以一个大于1的因子α,那么在经过
L 层后,梯度会变为原来的
解决方案
梯度消失和梯度爆炸问题不仅仅是由于激活函数的导数或权重初始值过大引起的,还与网络的结构、层数以及优化算法的选择密切相关。为了缓解这些问题,可以采用ReLU激活函数、合适的权重初始化方法、梯度裁剪等技术。
