





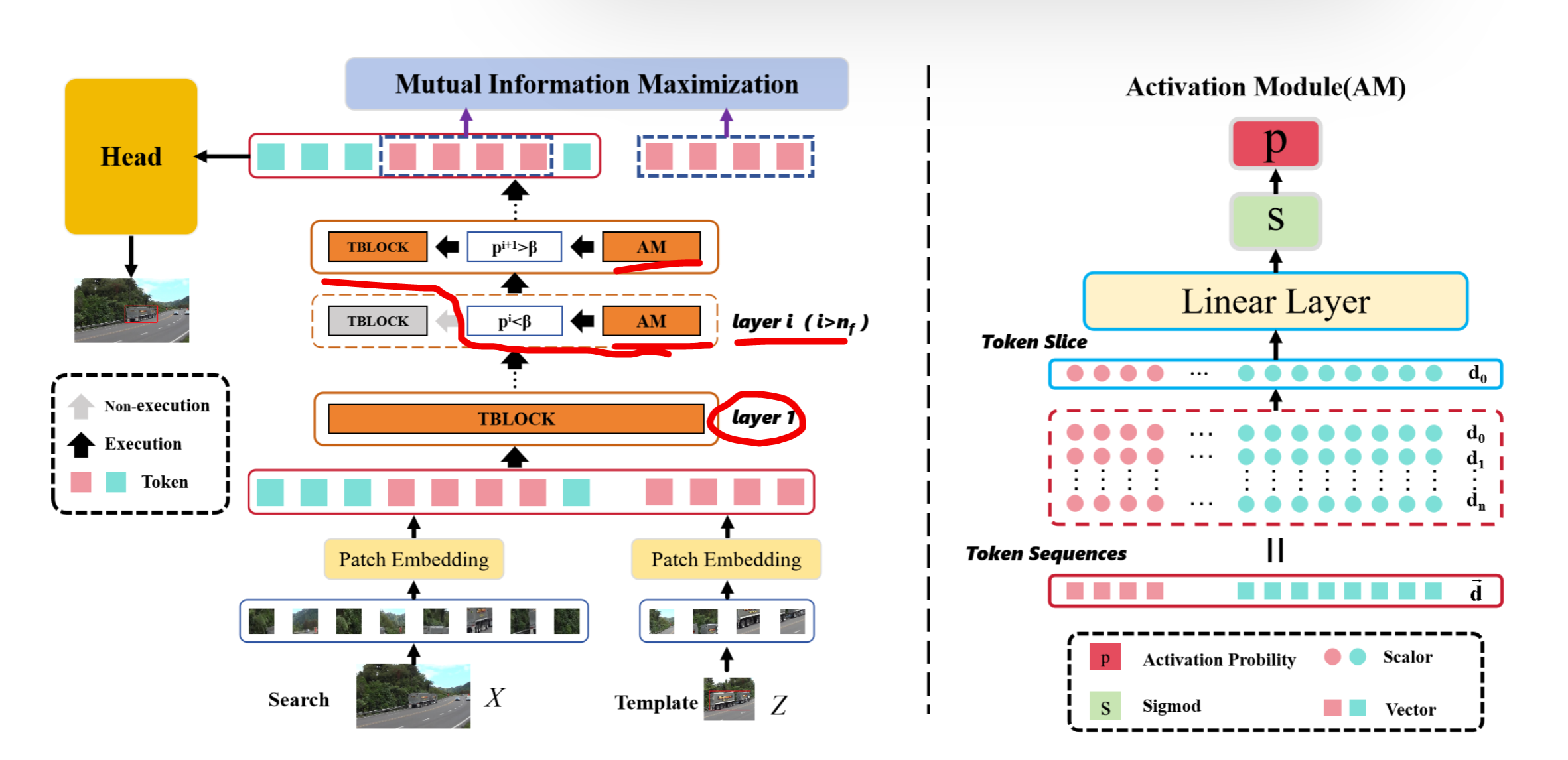
1. 输入处理
输入:
- 模板图像
,通常是初始帧或前一帧,尺寸较小,聚焦于目标物体。 - 搜索图像
,当前帧中需要搜索的区域,尺寸较大,覆盖目标可能的移动范围。
分块:
和 分为 大小的块,数量分别为:
线性投影:
- 每个小图像块通过线性层映射为维度
的嵌入向量。
位置编码:
- 使用可学习的位置编码,保留空间信息。
2. 激活模块 (AM)
2.1 基本定义
考虑第
层 ,tokens 的总数记为 ,嵌入向量的维度记为 。 第
层输出的 tokens 记为 。 第
层 Transformer 块输出的标记切片表示为:
其中是标准单位向量。 线性层标记为
。
2.2 激活模块公式
激活模块(Activation Module, AM)表示为:
其中:
表示第 层 Transformer 块的激活概率。 为 sigmoid 激活函数: 。
2.3 激活规则
- 设
为激活概率阈值。 - 若
,则第 层 Transformer 块被激活。 - 否则,跳过第
层,直接将第 层的输出 tokens 传递给第 层。
- 若
2.4 强制激活与稀疏性
强制激活:
- 若所有
个 Transformer 块都未被激活,则无法计算模板图像和搜索图像之间的相关性。 - 因此,设定前
层始终保持激活状态,以确保基础信息的传递。
- 若所有
区块稀疏性损失
: 若所有输入经过 AM 都使 Transformer 模块激活,会导致效率降低。
引入区块稀疏性损失,鼓励在平均情况下停用更多的 Transformer 块:
其中为常数,与 共同控制模块的稀疏性。
3. 通过互信息 (MI) 最大化表征视图不变性 (VIR)
3.1 互信息 (MI) 定义
给定两个随机变量
其中:
是联合概率分布。 是边缘概率分布。 是库尔贝克-莱布勒散度。
3.2 基于 JSD 的 MI 估计
由于现实中无法直接估计 MI,采用基于詹森-香农散度 (JSD) 的 Deep
InfoMax MI 估计器:
其中:
是一个神经网络,将输入空间映射到实数空间。 是 softplus 函数。
3.3 视图不变性损失
真实目标定位 token 表示为:
其中。 给定目标在搜索图像中的真实定位
,通过线性插值获得对应的 token:
视图不变性损失函数为:
4. 基于知识最大化的多教师知识蒸馏 (MD)
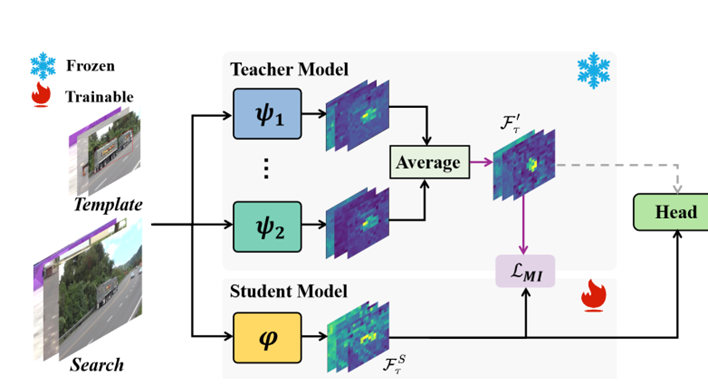
4.1 教师模型与学生模型
- 教师模型:使用 3 种已有的跟踪模型(AVTrack-DeiT、AVTrack-ViT 和 AVTrack-EVA),提供多样化且高质量的教师模型。
- 学生模型:选择自相似结构,使用较小的 ViT 主干网(一半 ViT 块),具有模块化和可扩展特性。
4.2 教师输出处理
平均所有教师的预测结果,得到聚合特征表示:
使用温度
对模型输出进行软化处理:
其中。
4.3 互信息最大化
目标函数为:
在蒸馏训练中,使用
和教师模型的总损失函数的加权和来训练学生模型。
5. 预测头和训练目标
5.1 拐角检测头
对搜索图像的特征进行处理,直接估计目标物体的边界框。
生成 3 个输出:
- 目标分类分数
,表示每个位置是目标中心的概率。 - 局部偏移
,用于微调目标位置的偏移量。 - 归一化边界框大小
,表示边界框的宽度和高度。
- 目标分类分数
根据分类分数的最大值确定目标的粗略位置:
结合局部偏移和边界框大小,最终确定目标的边界框:
5.2 总损失函数
总损失函数为加权焦点损失:
其中:, 。 , 。
在蒸馏阶段,总损失为:
其中。
核心
- 动态激活模块:通过稀疏性损失实现按需计算,效率提升约30%。
- 视图不变性学习:基于MI最大化,增强模型对视角变化的鲁棒性。
- 多教师蒸馏:轻量化学生模型性能接近教师,计算量减少50%。
